LUMI-O object storage¶
Why do I kneed to know this?¶

Most LUMI users will be unfamiliar with object storage. It is a popular storage technology in the cloud, with Amazon AWS S3 as the best known example.
On LUMI, the LUMI-O object storage system is probably the best option to transfer data to and from LUMI. Tools for object storage access often reach a much higher bandwidth than a single sftp connection can reach.
Object storage is also a good technology if you want a backup of some of your data and want to make that backup on LUMI itself. The object storage is completely separate from the regular storage of LUMI and hence offers additional security, though not as secure as if you would make a backup at a different compute centre.
In some research communities where cloud computing is more common, some datasets may come in cloud-optimised formats, i.e., formats optimised for object storage. Putting such data on the parallel file system without completely changing the data format is usually not a good idea.
In this section of the notes, we will discuss the properties of object storage and show you how to get started. It is by no means meant as a reference manual for all tools that one can use.
In short: What is LUMI-O?¶


LUMI-O is an object storage system (based on Ceph). Users from Finland may be familiar with Allas, which is similar to the LUMI object storage system, though LUMI doesn't provide all the functionality of Allas.
Object file systems need specific tools to access data. They are usually not mounted as a regular filesystem (though some tools can make them appear as a regular file system) and accessing them needs authentication via temporary authentication keys that are different from your ssh keys and are not only bound to you, but also to the project for which you want to access LUMI-O. So if you want to use LUMI-O for multiple projects simultaneously, you'll need authentication keys for each project.
Object storage is not organised in files and directories. A much flatter structure is used with buckets that contain objects:
-
Projects: LUMI-O works with "single user tenants/accounts", where the LUMI project number is both the tenant/account and LUMI-O project. So the individual users in a LUMI project are not know on LUMI-O and all users in a LUMI project have the same access to LUMI-O.
-
Buckets: Containers used to store one or more objects. Object storage uses a flat structure with only one level which means that buckets cannot contain other buckets.
-
Objects: Any type of data. An object is stored in a bucket.
-
Metadata: Both buckets and objects have metadata specific to them. One element of the metadata is the name of the bucket or object. But metadata can also contains the access rights to the bucket or object. While traditional file systems have fixed metadata (filename, creation date, type, etc.), an object storage allows you to add custom metadata in the form of (key, value) pairs.
Objects can be served on the web also. This is in fact how recordings of some of the LUST courses are served currently. However, LUMI-O is not meant to be used as a data publishing service and is not an alternative to services provided by, e.g., EUDAT or several local academic service providers.
The object storage can be easily reached from outside LUMI also with full access
control (and without webbrowsers). In fact, during
downtimes, LUMI-O is often still operational as its software stack is managed completely
independently from LUMI. It is therefore also very well suited as a mechanism for data
transfer to and from LUMI. Moreover, tools for object storage often perform much better
on high latency long-distance connections than tools as sftp.
LUMI-O is based on the Ceph object file system. It has a total capacity of 30 PB. Storage is persistent for the duration of a project. Projects get a quota of 150 TB and can create up to 1K buckets and 500K objects per bucket. These quota are currently fixed and cannot be modified. Storage on LUMI-O is billed at 0.5 TB·hour per TB per hour, half that of /scratch or /project. It can be a good alternative to store data from your project that still needs to be transferred but is not immediately needed by jobs, or to maintain backups on LUMI yourself.
A comparison between Lustre and LUMI-O¶
Or: What are the differences between a parallel filesystem and object storage?


Integration with the system
The Lustre parallel filesystem is very closely integrated in LUMI. In fact, it is the only non-local filesystem that is served directly to the compute nodes. Other remote filesystems on the Cray architecture are served via DVS, Data Virtualisation Service, a service that forwards requests to the actual filesystem services running on management nodes. HPE Cray does this to minimise the number of OS daemons running in the background. Client software on the compute and login nodes must also fairly closely match the server software on the actual Lustre servers. As a result of all this, the Lustre software has to be updated with all other system software on LUMI and, e.g., the Lustre filesystems are not available when LUMI is down for maintenance.
The LUMI-O object storage system on the other hand, is a separate system, though located physically fairly close to LUMI. Its software setup is completely independent from the software on the LUMI supercomputer itself. It has a regular TCP/IP connection to LUMI, but all other software to access data on LUMI-O from LUMI runs entirely in user space. Client software also hardly depends on the version of the Ceph server software as the protocol between both is fairly stable. As a result, upgrades of LUMI do not affect LUMI-O and vice-versa, so LUMI-O is almost always available even when LUMI is down. Moreover, the server software of LUMI-O can often be upgraded on-the-fly, without noticeable downtime. Client and server also communicate through a web-based API.
Organisation of data
The organisation of data is also very different on Lustre and LUMI-O. Lustre, although very different of the local filesystem(s) on your laptop or smartphone or more traditional networked filesystems common for networks of PCs or workstations, uses the same organisation of data as those filesystems. Data is organised in files stored in a hierarchical directory structure. In fact, Lustre behaves as much as possible as other classical shared filesystems: Data written on one compute node is almost immediately noticed on other compute nodes also. (In fact, this is also the main cause of performance problems for some operations on Lustre.)
These files can be read, written, modified and/or appended, and deleted. So one can change only a fraction of the data in the file without working on the other data, and different compute nodes can write to different parts of a file simultaneously.
The object storage system puts data as objects in buckets, and buckets are on a per-project basis. So there is basically a 3-level hierarchy: project, buckets and objects, with each level just a flat space. Bucket names have to be unique within a project, and object names have to be unique within a bucket.
Buckets cannot contain other buckets (contrary to directories which can contain other directories). Objects are not really arranged in a hierarchy, even though some tools make it appear as if this is the case by showing them in a directory tree-like structure based on slashes used un the name of the objects, but this structure is really just created based on those names and you will notice that structuring the objects like this in a view is actually a rather expensive operation in client software as the software always needs to go through all objects in the bucket and select the appropriate ones.
Objects are managed through simple atomic operations. One can put an object in the object storage, get its content, copy an object or delete an object. But contrary to a file in Lustre, the object cannot be modified: One cannot simply change a part of the content, but the object needs to be replaced with a new object.
Some tools can do multipart uploads: An large object is uploaded in multiple parts (which
can create more parallelism and hence have a higher combined bandwidth), but these parts
are actually objects by themselves that are combined in a single object at the end.
If the upload would get interrupted, the parts would actually continue to live as
separate objects unless a suitable bucket policy is set
(and we have run into issues already with a user depleting their quota on LUMI-O with
stale objects from failed multipart uploads).
The configuration that the LUMI-O tools generate for s3cmd enables multipart uploads of
big objects.
Optimised for?
Lustre is optimised first and for most for bandwidth to the compute nodes when doing large file I/O operations from multiple nodes to a file. This optimisation for performance also implies that simpler schemes for redundancy have to be used. Data is protected from a single disk failure and on most systems even from dual disk failure, but performance will be reduced during a disk repair action and even though the server functions are usually done in high availability pairs, we have seen more than one case where a server pair fails making part of the data inaccessible.
The LUMI-O object storage is much more optimised for reliability and resilience. It uses a very complicated internal redundancy scheme. On LUMI-O each object is spread over 11 so-called storage nodes, spread over at least 6 racks, with never more than 2 storage nodes in a single rack. As only 8 storage nodes of an object are needed to recover the data of an object, one can even lose an entire rack of hardware while keeping the object available.
Access
Lustre, as it is fully integrated in LUMI (or any other supercomputer that uses it), has no separate authentication. You log on to LUMI and you have access to files on the Lustre file system based on permissions: your userid and the linux group(s) that you belong to. You will see your files as on any other POSIX file system. No external access is possible and it depends completely on the authentication system of LUMI running and working properly.
The LUMI-O object storage works with a separate credentials-based authentication system. These credentials have to be created first in one of two ways that we will discus later and they have a very finite lifetime after which they need to be regenerated (when expired) or extended (if you do so before expiration).
In fact, in LUMI-O, projects are handled as so-called "single user tenants/accounts": the project numerical ID (e.g., 465000001) is both the tenant/account name and project name. LUMI-O will not further distinguish between the users in a LUMI project. Hence it is definitely not an option to make a backup from your home directory in a way that it would be secured from access by other users in your LUMI project.
LUMI-O clients and servers talk to each other via a web based API. There is a whole range of tools for all popular operating systems that support this API, both command line tools and GUI tools. In this world, external access is natural. There is really no difference in accessing LUMI-O from LUMI or from any other internet-connected computer. It is even possible to access LUMI-O via a web browser if such access is set up properly. It is documented in the bottom parts of the "Advanced usage of LUMI-O" page in the LUMI docs.
MDS and ODS
Both Lustre and the Ceph object storage system work with metadata servers (MDS) and object data servers (ODS), but this is where the similarities end. The internal organisation of MDS and ODS is completely different in both, but those differences are not that important at the level of this tutorial.
Parallelism is key to performance
Both Lustre and LUMI-O require parallel access to get the optimal performance. How that parallelism is best organised, is very different though.
Lustre will perform best when large accesses are made to large files by multiple processes preferably on multiple nodes of the supercomputer. Parallelism through accessing different files from each process will be far less performant and may even lead to an overload on the metadata servers.
The object storage is different in that respect: As operations on objects are atomic, they should also be accessed from a single process. But multiple processes or threads should access multiple objects simultaneously for optimal access. However, even in those cases the bandwidth will be somewhat limited as the network connection between LUMI-O and LUMI is a lot less as between the Lustre object data servers and the LUMI compute nodes, as both are fully integrated in the same high performance interconnect.
Cost
The hardware required for Lustre may not be as expensive as for some other fileservers, but a hard disk based Lustre filesystem is still not cheap and if you want a performant flash based filesystem that can endure a high write load also and not only a high read load, it is very expensive. The LUMI-O hardware is a lot cheaper, though this is also partly because it has a lower bandwidth.
The billing units accounted for storage on LUMI reflect the purchase cost per petabyte for LUMI-O and the Lustre filesystems, with the object storage billed at half the price of the hard disk based Lustre filesystems and the flash based Lustre filesystem at 10 times the cost of the hard disk based one.

The differences between a parallel file system and object storage also translate into differences in "file formats" between both (with "file formats" between quotes as we cannot speak about files on the object storage). The best way of managing life data on both systems is very different.
Take as an example netCDF versus the zarr data format. Both are popular in, e.g., earth and climate science. NetCDF is a file format developed specifically with supercomputers with large parallel file systems in mind, while zarr is a cloud-optimised technology. You cannot work with netCDF files from an object storage system as they would be stored as a single object and only atomic operations are possible. Zarr on the other hand is a format to store large-scale N-dimensional data on an object storage system by breaking it up in a structured set of objects that each can be accessed with atomic operations. But if you bring that hierarchy of objects as individual files onto a parallel file system, you risk creating problems with the metadata server as you will be dealing with lots of small files.
There is no "best" here: both are different technologies, developed with a specific purpose in mind, and which one you should use is hence dictated by the technology that you want to use to store your data.
Accessing LUMI-O: General principles¶

Access to LUMI-O is based on temporary credentials that need to be generated via one of two web interfaces: Either a dedicated credential management portal, or the Open OnDemand interface to LUMI that we discussed in the "Getting access" session. We will discuss both options in this chapter of the notes.
There are currently three command-line tools pre-installed on LUMI
to transfer data back and forth between LUMI and LUMI-O:
rclone
(which is the easiest tool if you want both public web-accessible and private data),
s3cmd
and restic.
All these tools are made available through the lumio module that can
be loaded in any software stack.
The boto3 Python package
is a good choice if you need programmatic access to
the object storage. Note that you need to use fairly recent versions which in turn
require a more recent Python than the system Python on LUMI (but any of the cray-python
modules would be sufficient). As it is better to containerize Python installations with
many packages on LUMI, and as most users also prefer to work with virtual environments,
it is not pre-installed on LUMI as it would be impossible to embed it into the Cray
Python distributions.
But you can also access LUMI-O with similar tools from outside LUMI. Configuring them may be a bit tricky and the LUMI User Support Team cannot help you with each and every client tool on your personal machine. However, the dedicated credential management web interface can also generate code snippets or configuration file snippets for various tools, and that will make configuring them a lot easier.
There also exist GUI-based tools for all popular operating systems. Almost every tool suitable for AWS S3 storage should also work for LUMI-O when properly configured.
The Open OnDemand web interface also has a tool to show buckets and objects on LUMI-O in a folder-like structure (created based on object "names" with slashes) and can be used to upload and download objects, but it is not a substitute for the specific tools for object storage. When you upload or download via the web browser, you don't talk directly to LUMI-O, but you use a web browser that talks to the web server using web APIs, with all performance limitations of those protocols, and the web server then talks to LUMI-O.
The credential management web interface¶

One way to create the credentials to access LUMI-O, is via the the credential management web interface that can be found at auth.lumidata.eu. This system runs independently from LUMI, just as the object storage itself, and usually remains available during downtimes of LUMI. So even though you may prefer creating credentials via Open OnDemand, it is good to learn to use this system as it can still give you access to your data on LUMI-O while LUMI is down for maintenance.
Let's walk through the interface:
A walk through the credentials management web interface of LUMI-O
After entering the URL auth.lumidata.eu, you're presented with a welcome screen on which you have to click the "Go to login" button.
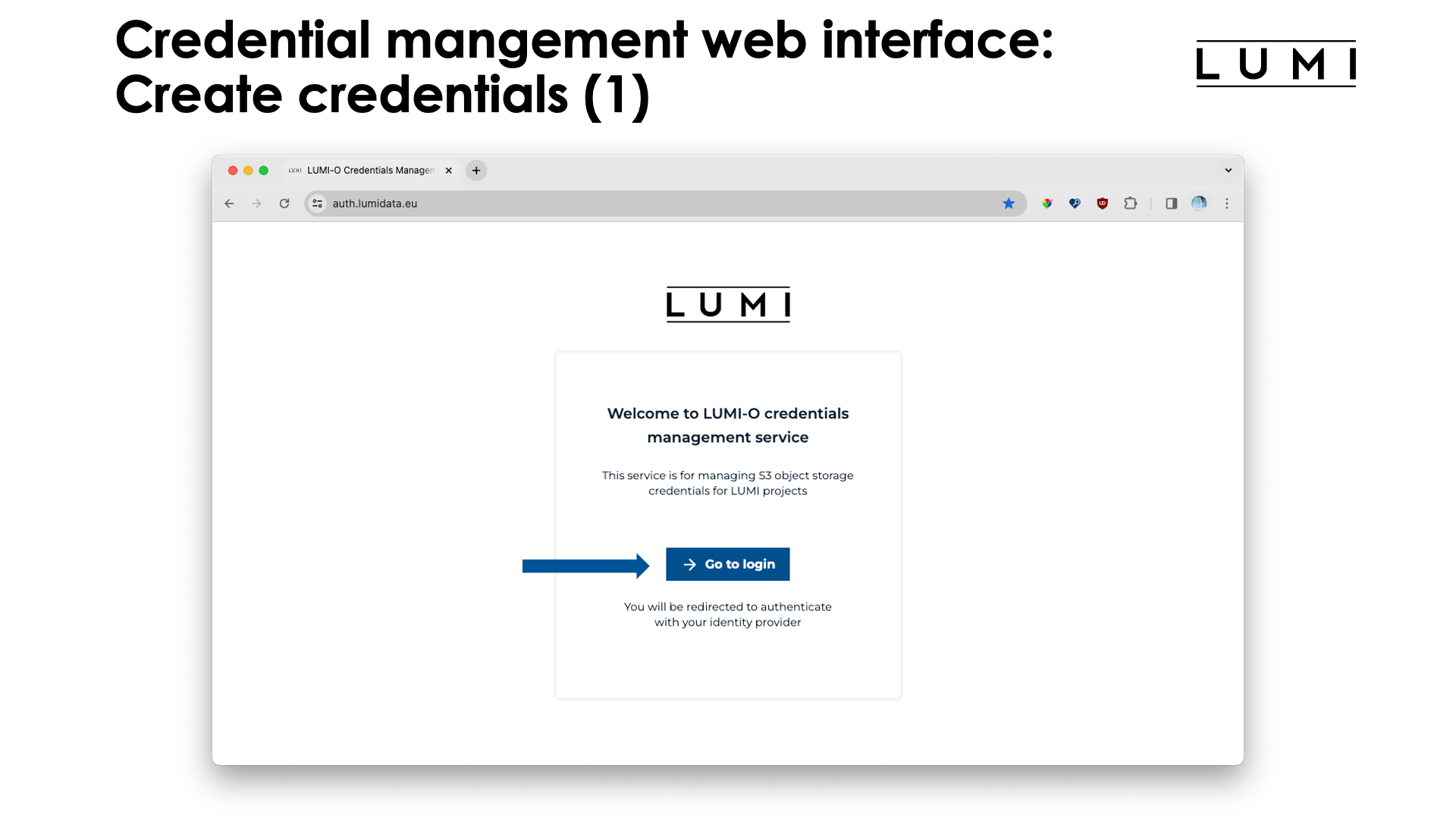
This will present you with the already familiar (from Open OnDemand) screen to select your authentication provider:
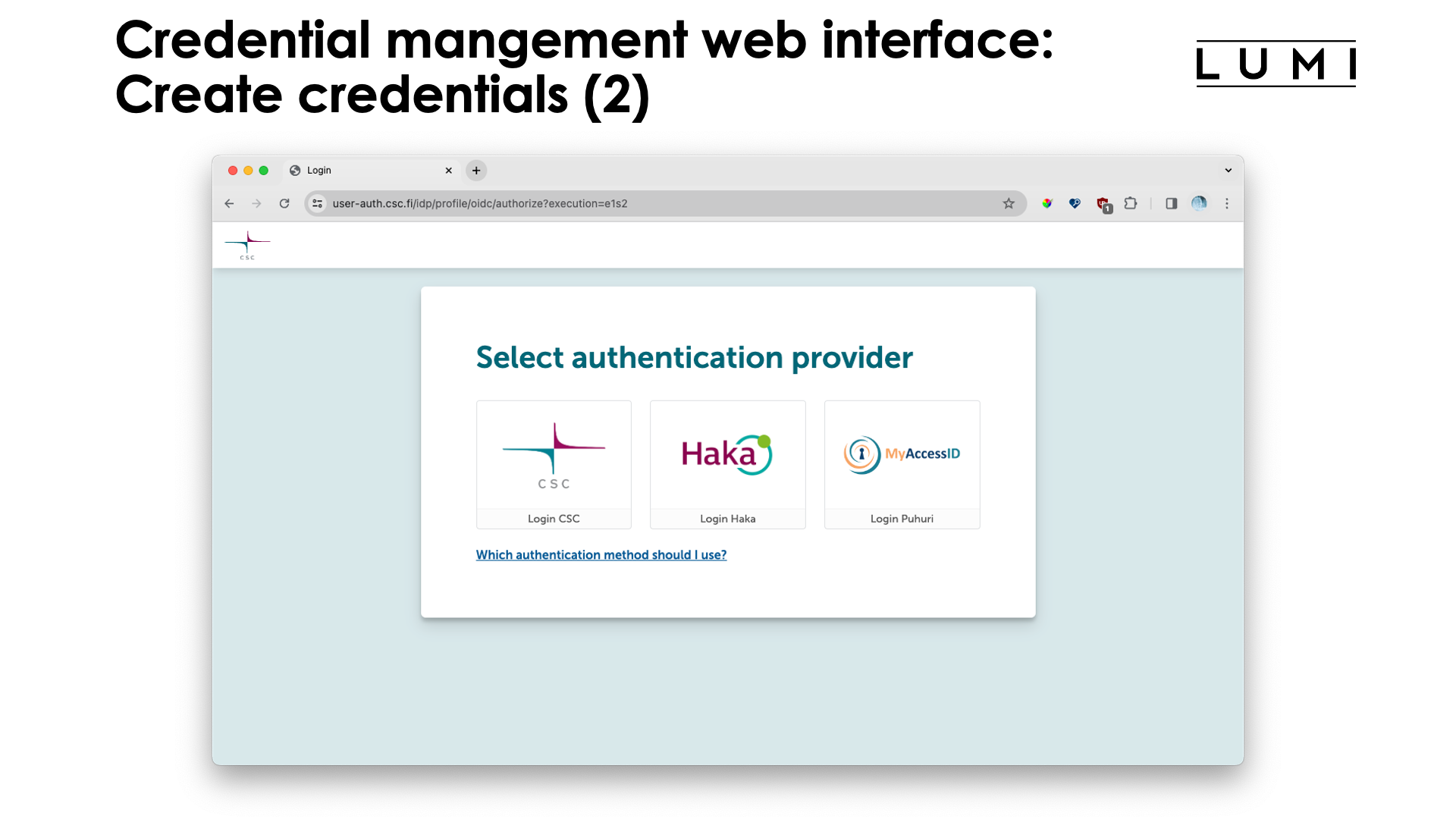
Proceed with login in through your relevant authentication provider (not shown here) and you will be presented with a screen that show your active projects:
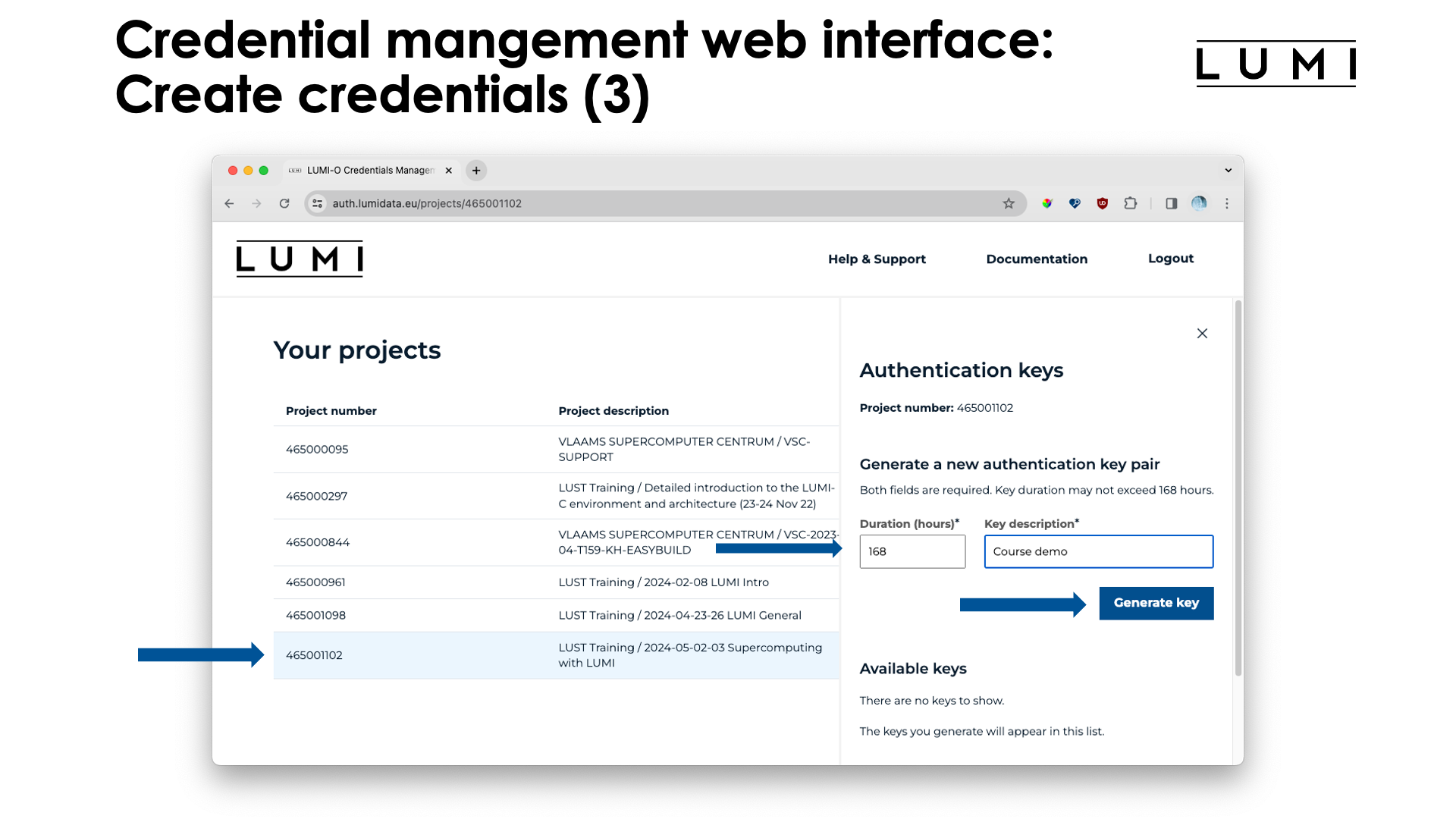
Click the project for which you want to generate access credentials (called "authentication keys" or "access keys" in the interface), and the column to the right will appear. Chose how long the authentication key should be valid (1 week or 168 hours is the maximum currently, but the life can be extended) and a description for the authentication key. The latter is useful if you generate multiple keys for different use. E.g., for security reasons you may want to use different authentication keys from different machines so that one machine can be disabled quickly if the machine would be compromised or stolen.
Next click on the "Generate key" button, and a new key will appear in the "Available keys" section:
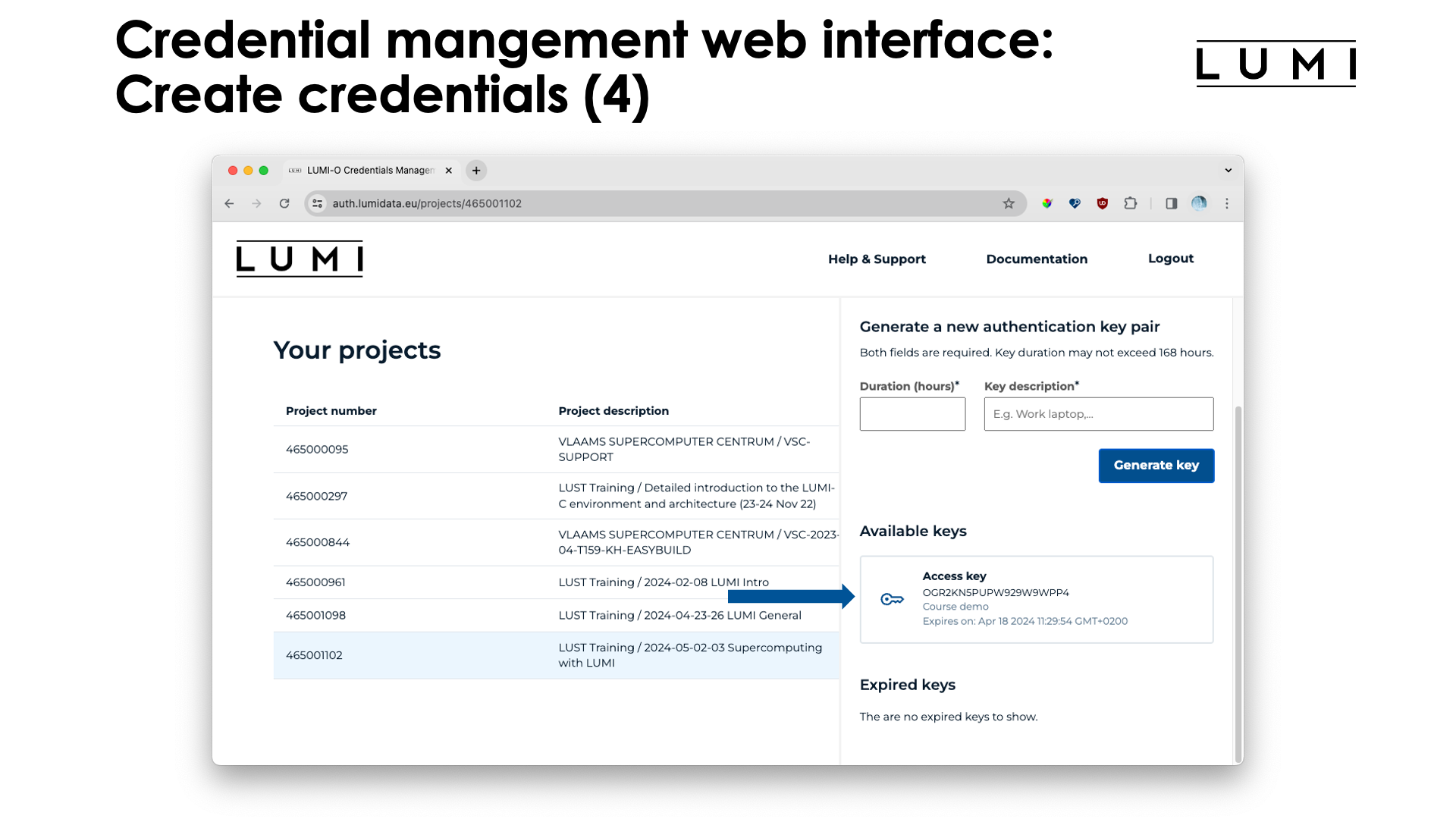
Now click on the key to get more information about the key:
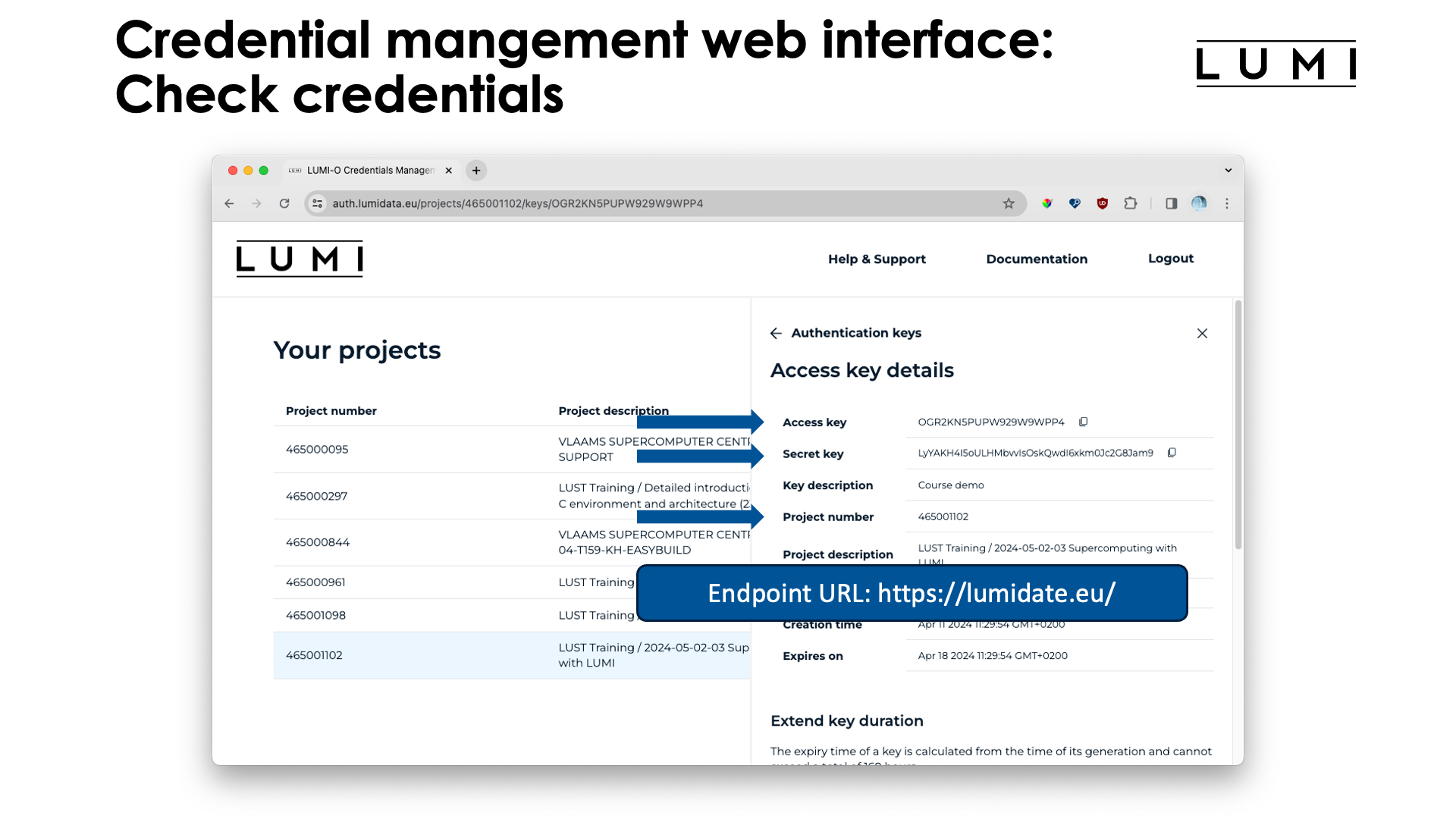
At the top of the screen you see three elements that will be important if you use the LUMI command line tool
lumio-conf to generate configuration files for rclone and s3cmd: the project number (but you knew that one),
the "Access key" and "Secret key". The access key and secret key will also be needed if you configure other clients,
e.g., a GUI client on your laptop, by hand. The other bit of information that is useful if you configure tools by hand,
is the endpoint URL, which is "https://lumidata.eu/" and is not shown in the interface.
Note: One more configuration parameter
LUMI-O requires path-style (https://projectnum.lumidata.eu/bucket) addressing to buckets.
The so-called virtual-hosted style (https://bucket.projectnum.lumidata.eu) is not supported.
From a technical point of view, this is because the
*.lumidata.eu wildcard TLS certificate can only represent one layer of subdomains
which is used for the project numbers.
Many clients default to path-style addressing, but some will require a configuration option or an environment variable.
Commonly used parameters and environment variables are use_path_style, force_path_style
or S3_FORCE_PATH_STYLE. Notably aws-sdk defaults to trying virtual-hosted style when reading public buckets.
Note that we can only give hints on how to do things, but the LUMI User Support Team cannot support any possible client and certainly not commercial ones to which we cannot get access.
Scrolling down a bit more:
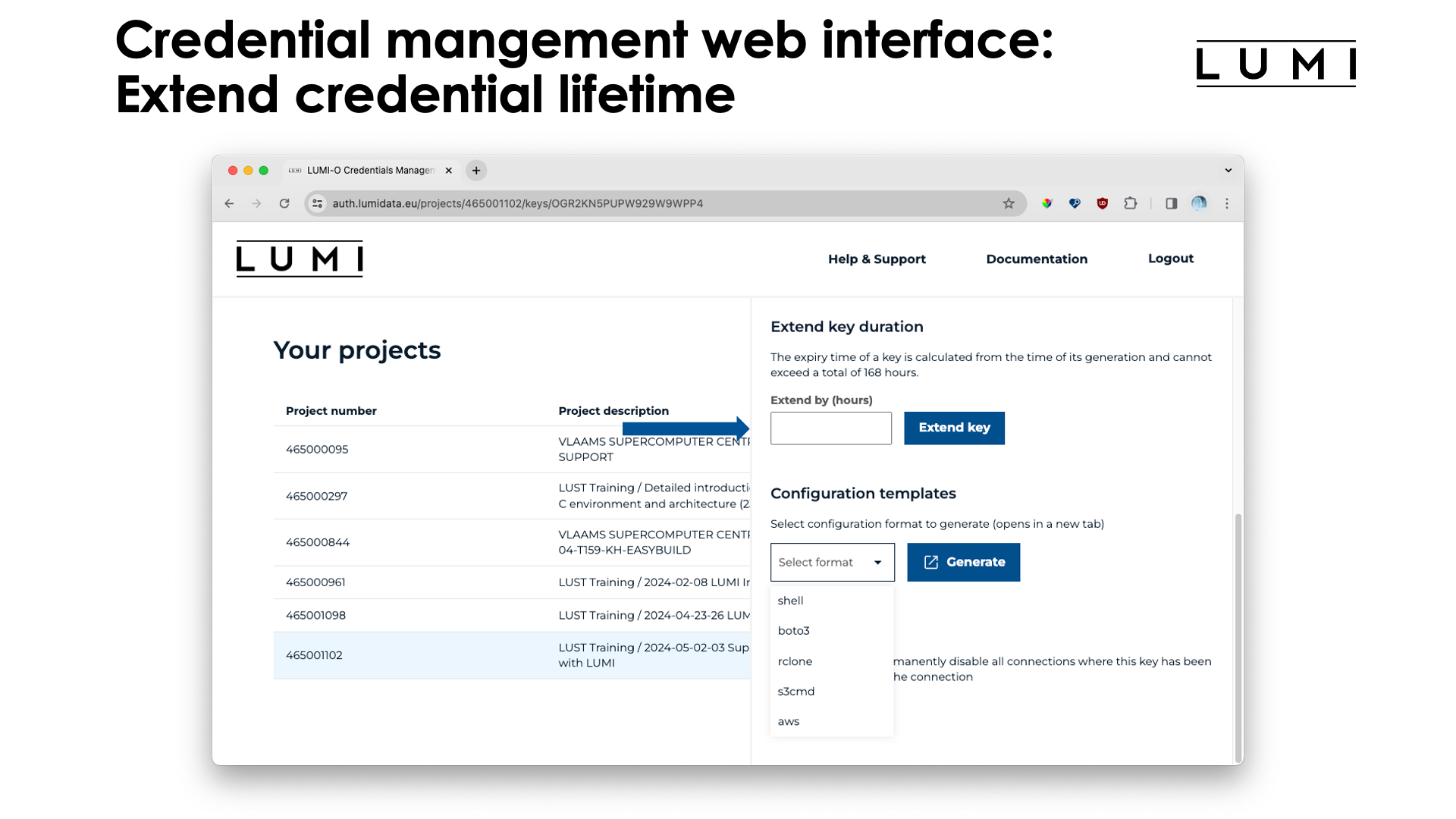
The "Extend key" field can be used to extend the life of the key, to a maximum of 168 hours past the current time. You can extend the life of an access key as often as you can, but it is not possible to create an access key that remains valid for more than 168 hours. This is done for security reasons as now a compromised key can only be used for a limited amount of time, even if you haven't noticed that the access key has been compromised and hence fail to invalidate the access key in the interface.
The credential management interface can also be used to generate snippets for configuration files for various tools:
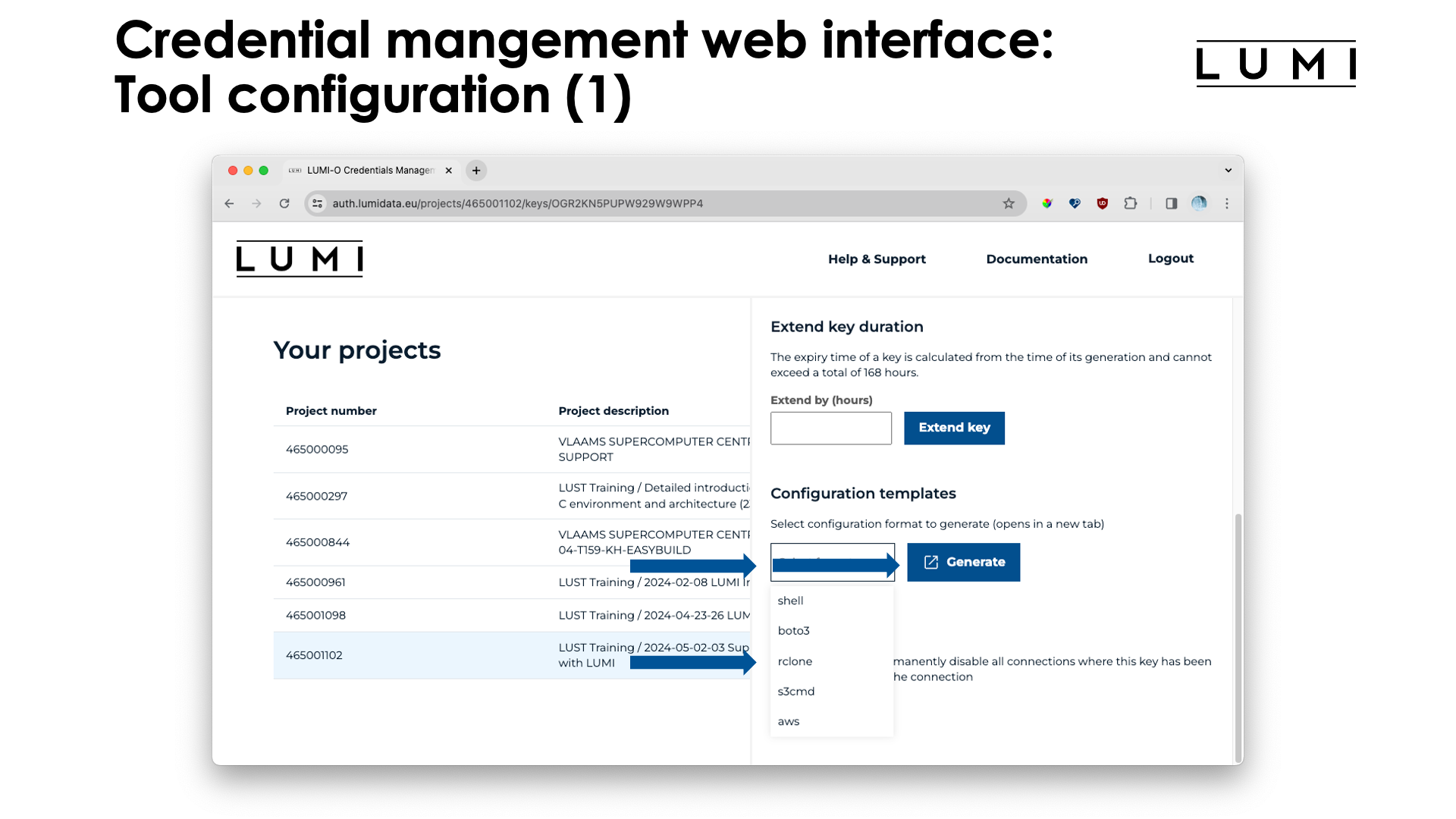
The "Configuration templates" is the way to generate code snippets or configuration file snippets for various tools (see the list on the slide). After selecting "rclone" and clicking the "Generate" button, a new screen opens:
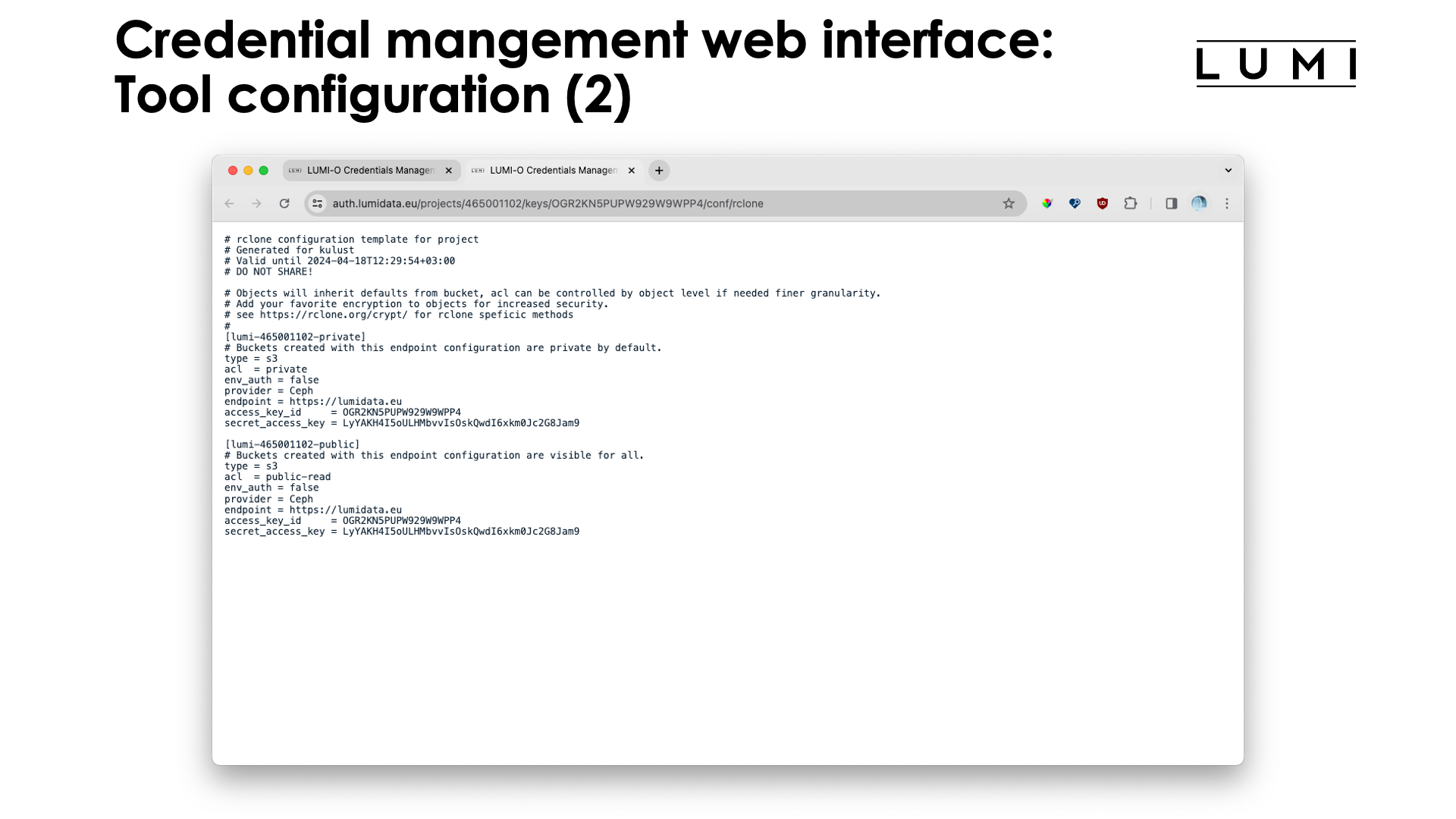
This screen shows us the snippet for the rclone configuration file (on Linux it is
~/.config/rclone/rclone.conf). Notice that it creates two so-called endpoints. In the slide
this is lumi-465001102-private and lumi-465001102-public, for storing buckets and objects which are private
or public (i.e., also web-accessible).
Credential management and access through Open OnDemand¶

The LUMI Open OnDemand-based web interface can also be used to generate
authentication keys for LUMI-O. It can create configuration files for
rclone and s3cmd but doesn't have all the other features of the dedicated credential
management web interface discussed above.
The "Home Directory" app can also be used to browse, download and upload objects and to
create buckets. It is a tool based on rclone and also provides a view similar to many
other viewers. The view is based on pseudo-folders which we will discuss below.
Note however that this interface is not a replacement for proper tools for access to object storage. Uploading and downloading objects is not done via object storage tools, but via web protocols. The web server talks to the object storage using proper tools, but to your browser using the regular web API upload and download features. Hence it is only suitable for relatively small objects and you'll quickly run into speed restrictions that native object storage tools will not have.
Let us now again walk through the interface.
A walk through the Open OnDemand web interface to LUMI-O
This demo was made with a project that course participants have no access to, but it gives the idea.
After entering the URL www.lumi.csc.fi, you're greeted with the usual login procedure that we discussed already. After logging in, you get the app overview screen:
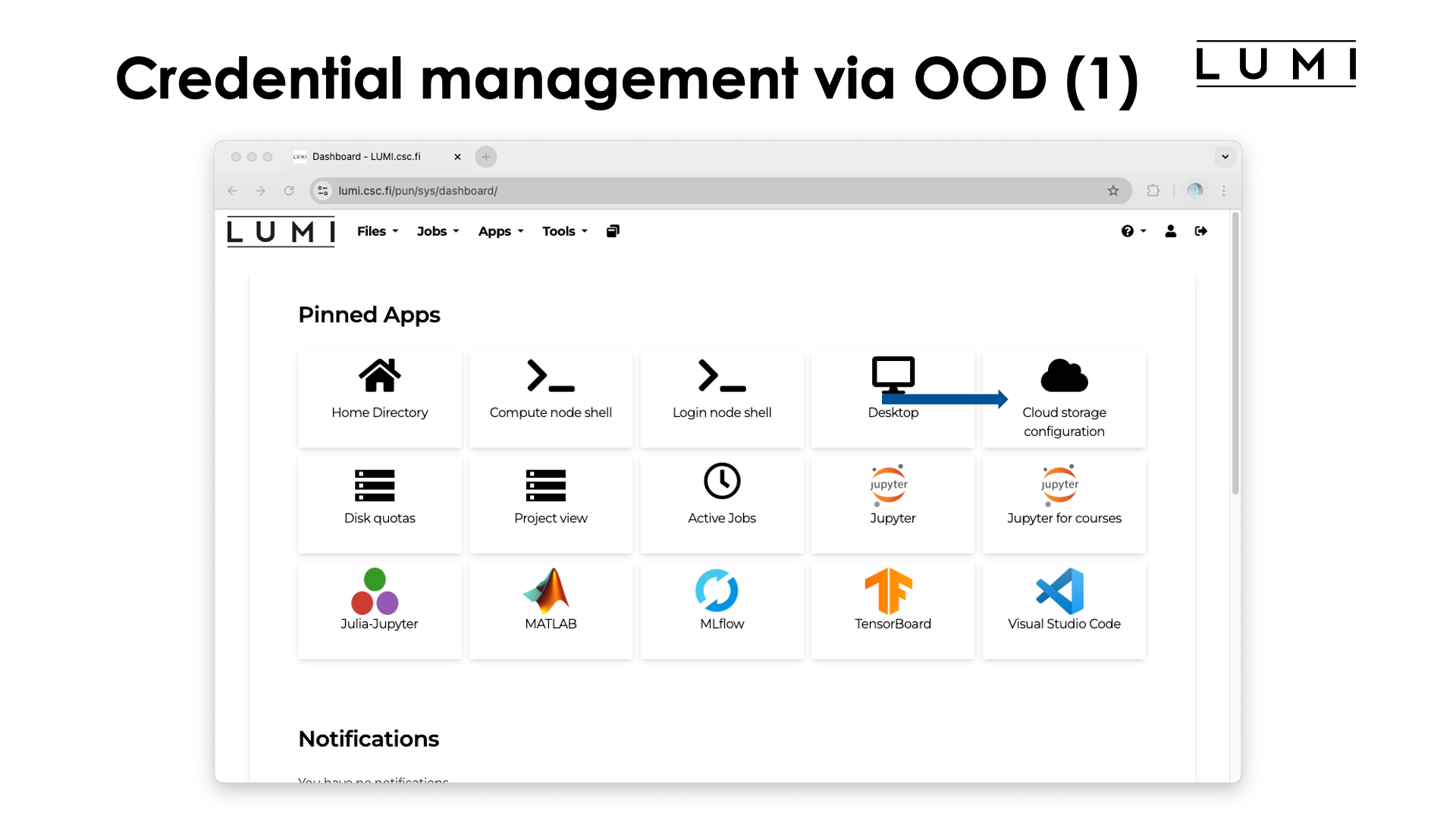
To create an authentication key and to configure rclone and s3cmd, open the
"Cloud storage configuration" app. You will be presented with the following screen:
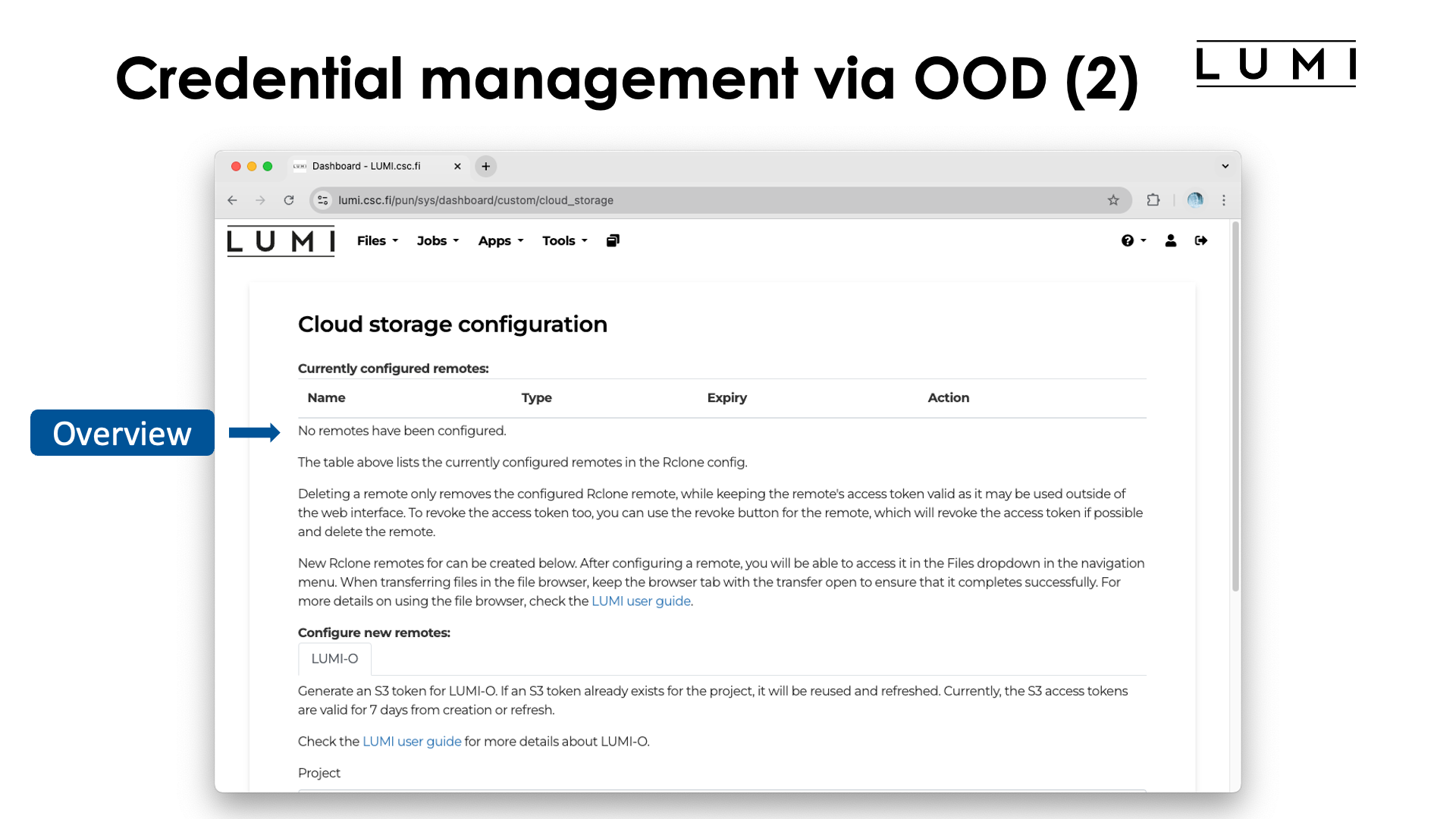
At the top of the screen there is an overview of currently configured remotes. These are actually
the endpoints for rclone. In this example, this section is still empty as no remotes are
configured for the user. Let's scroll down a bit:
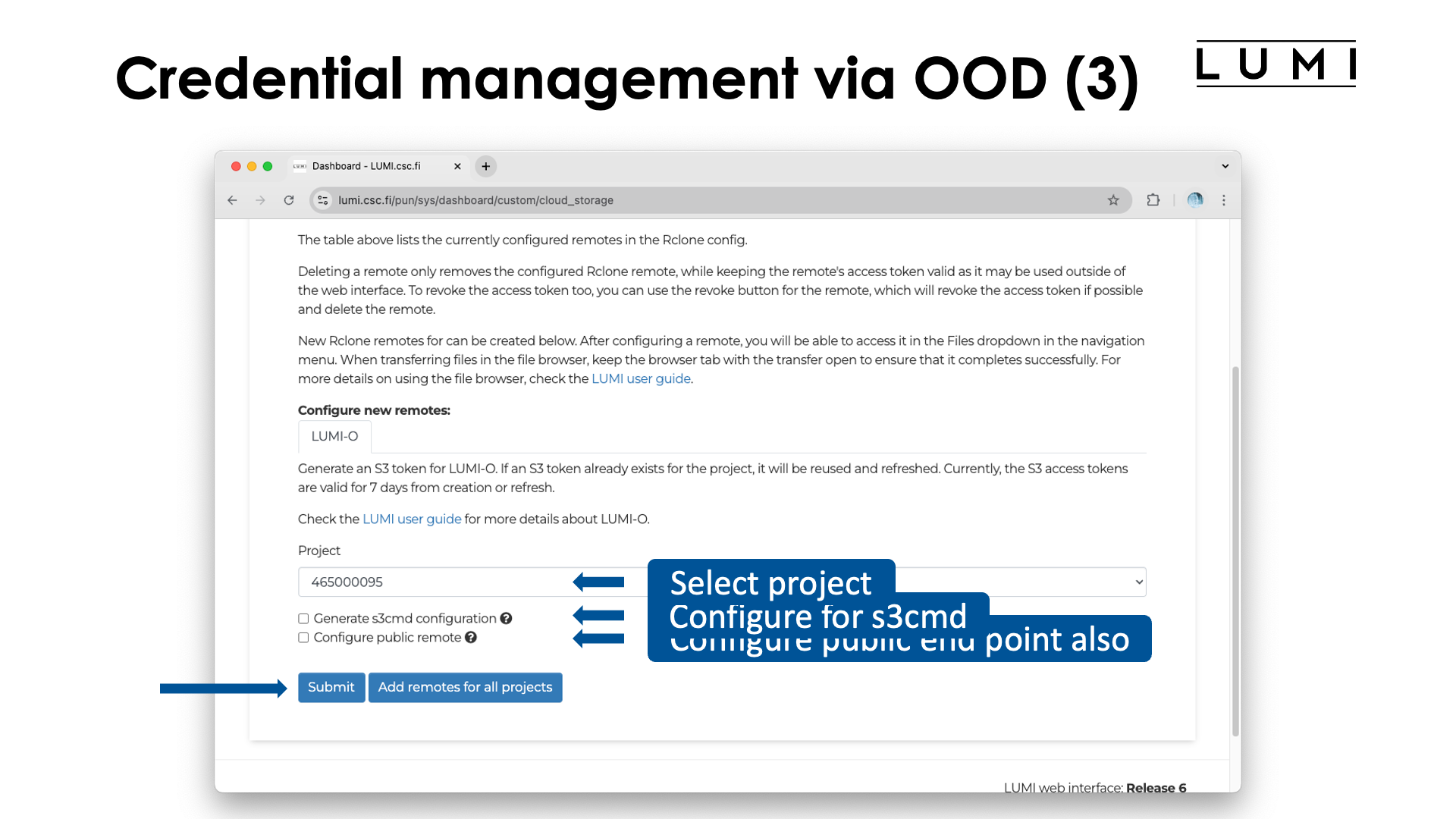
Here we see the part of the screen where we can create an authentication key. First select the project for which you want to create an authentication key.
Besides the authentication key, by default an rclone endpoint to create buckets and upload objects with
private access only will also be created and this cannot be turned off as the endpoint will also
be used by another app that we discuss later. However, two checkboxes enable the creation of
a configuration file for s3cmd and an rclone endpoint to create buckets and objects with public
access ACL can also be created.
The rclone endpoints are stored in the rclone configuration file
~/.config/rclone/rclone.cfg where they will replace the same endpoints for the project
if they are already present. Other endpoints will not be removed from the configuration file.
Finally, click the "Submit" button. If no suitable key exists, one will be created, and the requested endpoint and configuration file(s) will be created or updated. When a key is created, it is created with the maximum life span of 7 days (168 hours), but if a suitable one exists, it is currently not extended. (It appears that only a key with the description "lumi web interface" is properly recognised as the other key already existed but had its life span extended.)
We now notice some changes at the top of that screen:
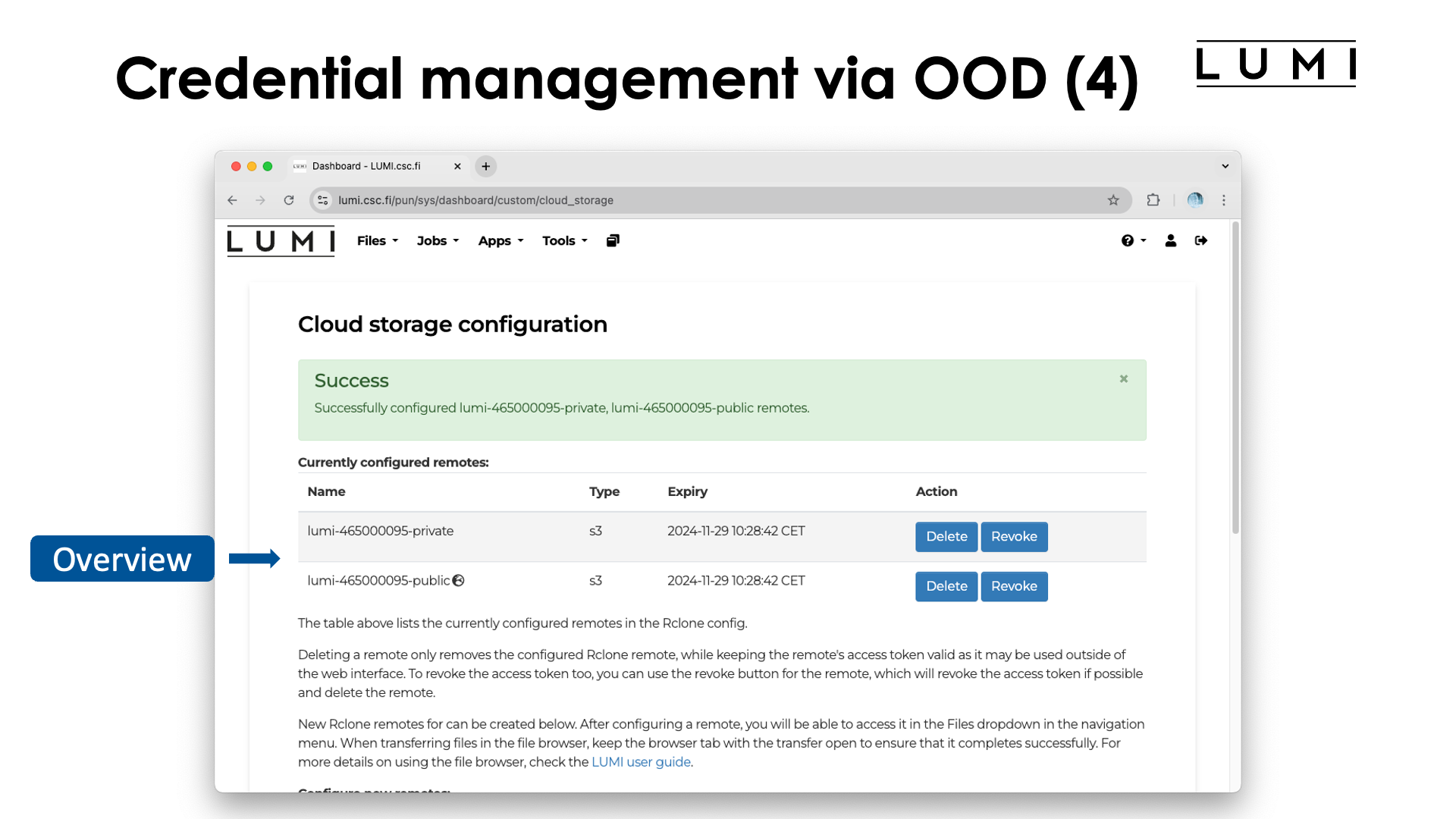
We've created both a private and a public rclone endpoint with the name
lumi-465000095-private and lumi-465000095-public respectively. These endpoints can also be used
with the command line rclone tool provided by the lumio module.
The "Delete" button can used to delete the endpoint only, but the authentication key will not be revoked, i.e., the
key remains valid. The "Revoke" button will invalidate the key and destroy the rclone endpoint(s) as
they don't make sense anymore.
Let's check the previously discussed dedicated web credentials portal:
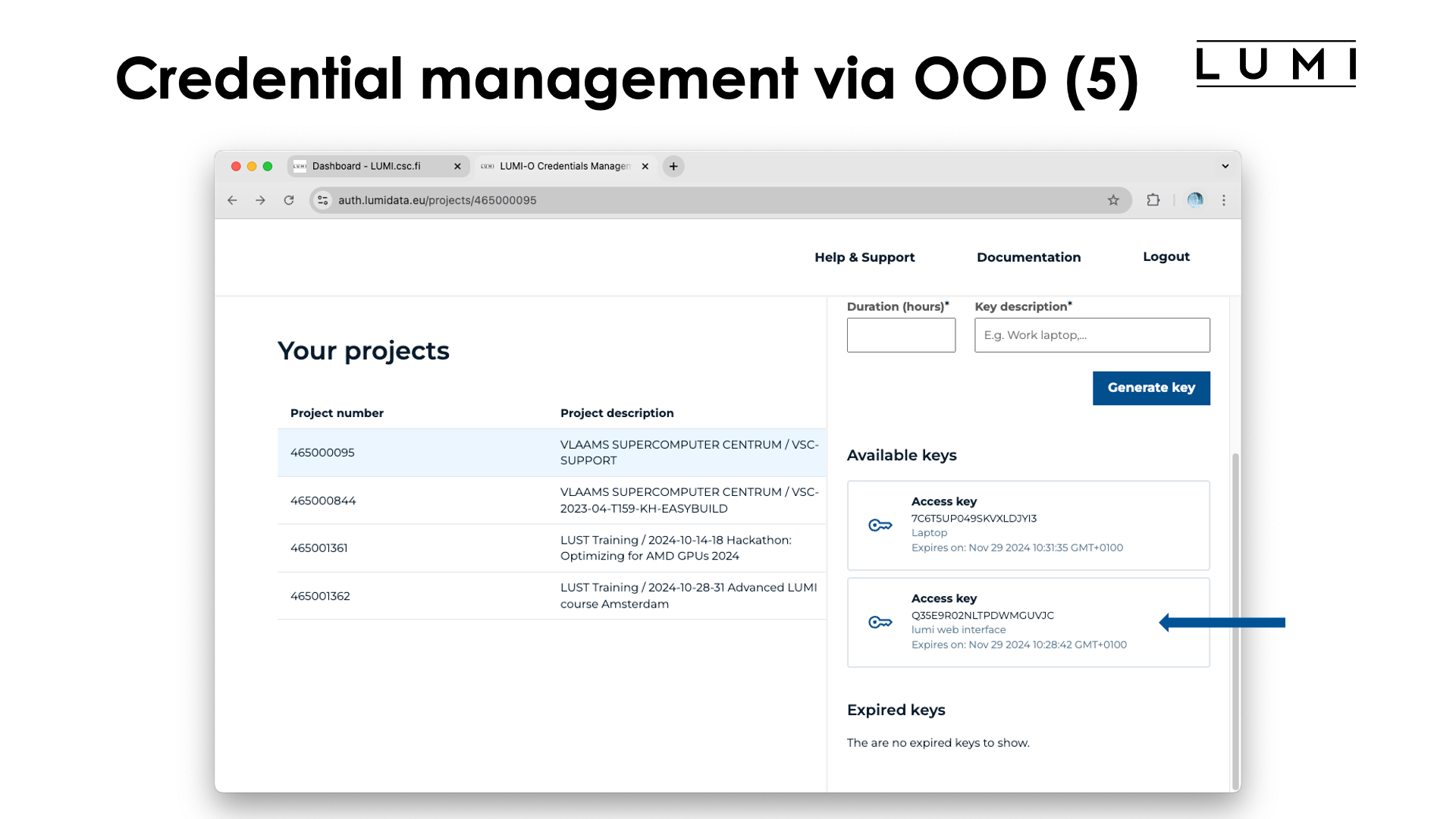
A key with the description "lumi web interface" is now visible, and this interface can still be used to extend its life span or create configuration file snippets for other tools. It is just another key.
(The screenshot is a bit misleading here. The other key "Laptop" actually existed but was not picked up by Open OnDemand, it is just that its life span was extended before making this screenshot which was probably a bad choice.)
Let's now also have a look at another Open OnDemand app that enables us to browse buckets and objects for the project for which we have created credentials:
We went back to the start screen of Open OnDemand and now open the "Home Directory" app.
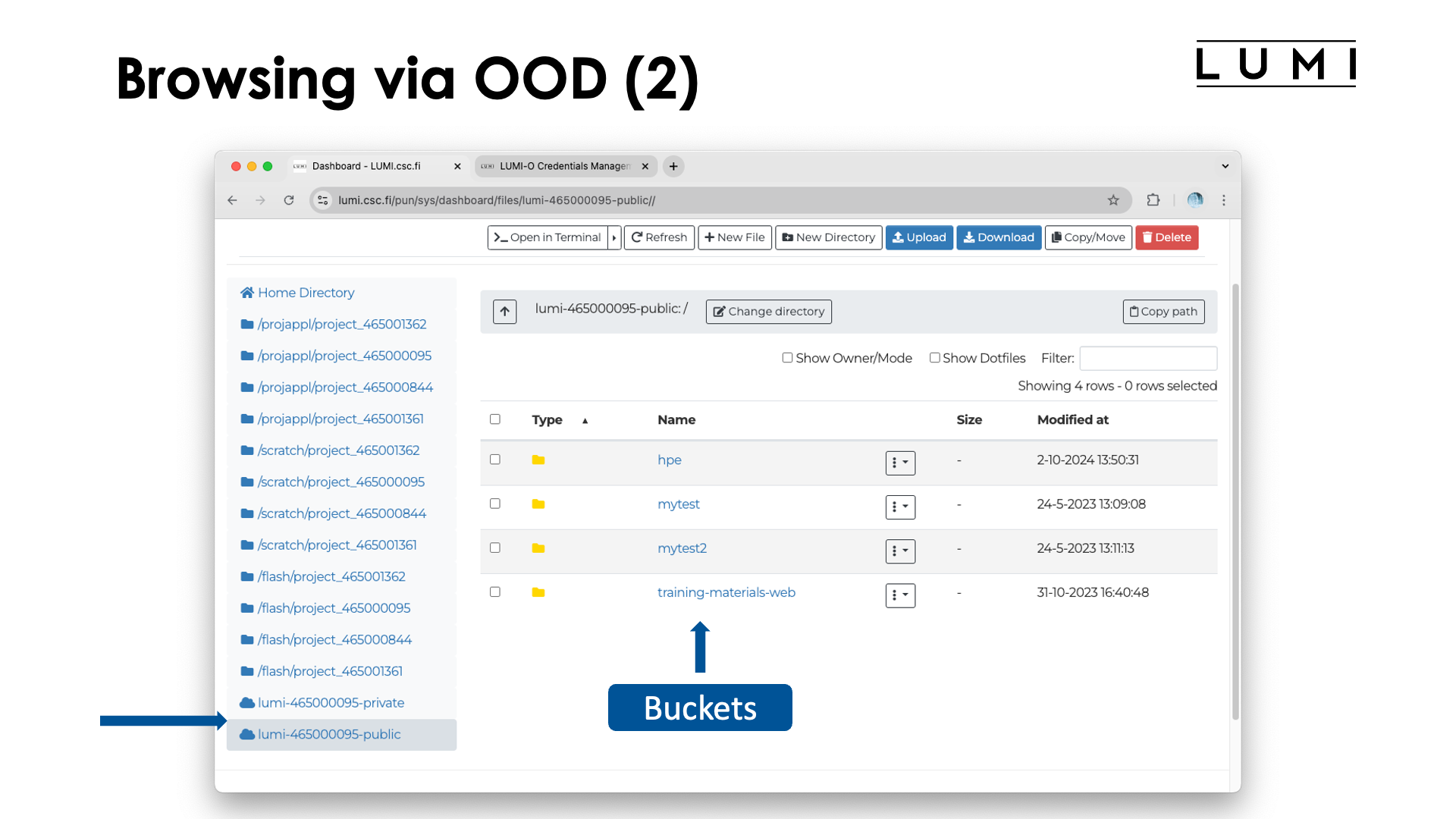
We now see our home directory and project, scratch and flash directory for all our projects, but also the two
endpoints that we just created (assuming we did indeed select the check box to create a public endpoint also). The screenshot
is taken after selecting lumi-465000095 in the left column and shows the buckets available to that project. Note that they
are shown in exactly the same way as directories (folders) would be shown for the regular filesystem, but in fact, they are
buckets with, e.g., all the naming restrictions of buckets.
Let's now select the training-materials-web bucket to arrive at:
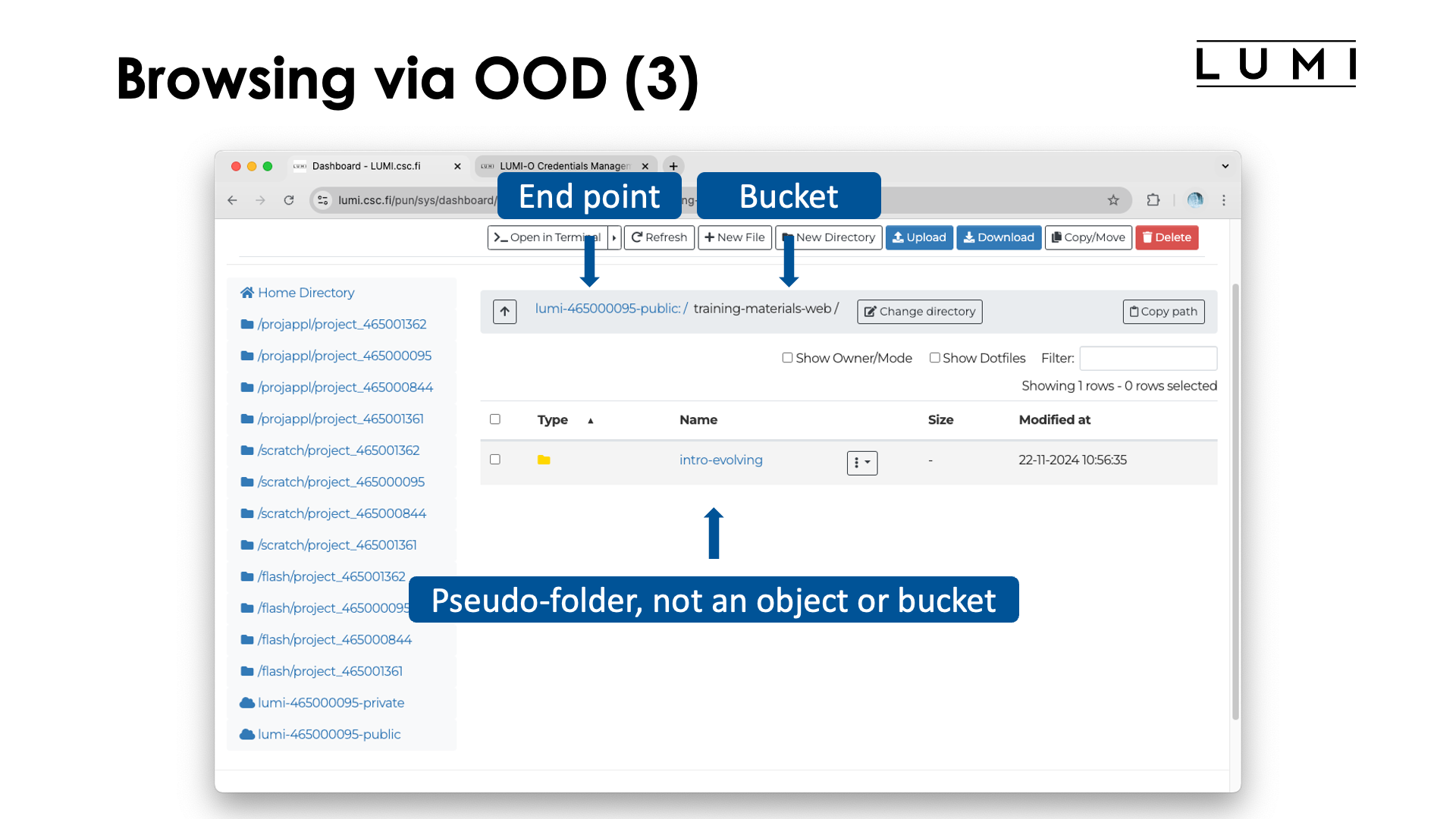
At the top of the right pane we now see the "path" lumi-465000095-public:/training-materials-web/.
This however is a pseudo-path: The first element is actually the rclone endpoint while the second element is the name of
the bucket. The screen also shows the folder intro-evolving. This is neither a bucket nor a true folder. It is an artificial
creation and if we click a bit further we will see what's going on:
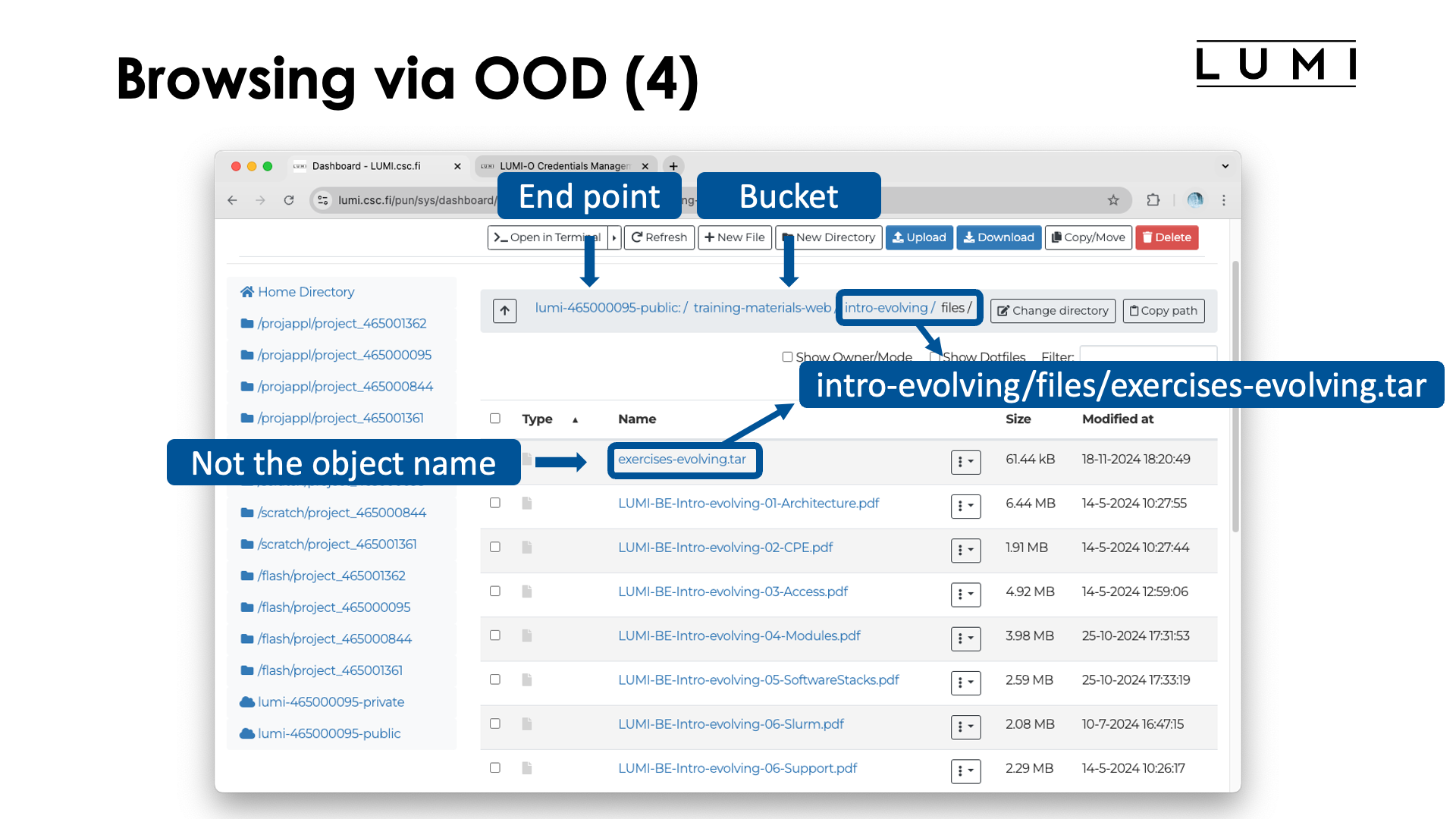
The top bar now shows lumi-465000095-public:/training-materials-web/intro-evolving.files/ while we also get a list
of elements that look like files. These are the objects, but don't be mistaken: The name of the first object in the
list is not exercises-evolving.tar, but it is the object named
intro-evolving/files/exercises-evolving.tar in the bucket training-materials-web in the project 46500095.
The slashes in the name are used to create a "pseudo-folder" view to bring more structure into the flat space of
objects, but the organisation internally in object storage is completely different from a regular filesystem.
Note that we would also see the same objects had we used the lumi-465000095-private endpoint in the right column:
Both are endpoints for the same project and the browser cannot distinguish between objects created via one or the
other endpoint. Those endpoints only matter when creating an object as they determine access rights.
Configuring LUMI-O tools through a command line interface¶


The materials in this section are only valid for the lumio/2.0.0 module and newer. lumio/2.0.0 is the default at the time of the course.
On LUMI, you can use the lumio-conf tool to configure rclone, s3cmd, aws
and the boto3 Python packages.
To access the tool, you need to load the lumio module first, which is always available.
The same module will also load a module that makes rclone, s3cmd and restic available.
aws and boto3 are not preinstalled though.
When starting lumio-conf, it will present you with a couple of questions: The project number
associated with the authentication key, the access key and the secret key. We have shown above where in the web
interface that information can be found.
For rclone, the tool will then add or replace the configuration for the project in the rclone
configuration file ~/.config/rclone/rclone.conf.
It will create two endpoints:
-
lumi-46YXXXXXX-privateis the end point to be used for buckets and objects that should be private, and -
lumi-46YXXXXXX-publicis the end point for data that should be publicly accessible.
It will also create an s3cmd configuration file. Since a s3cmd configuration
file can contain information for only one project, the following solution was chosen:
-
The tool creates the configuration file
~/.s3cfg-lumi-46YXXXXXXspecific for the project, -
and overwrites the
˜/.s3cfgconfiguration file with the new configuration.
So if you want to use s3cmd for only one project, or for the last project for which you used
lumio-conf, you can simply use it as in all the s3cmd examples, while if you want to use it
for more projects, you can always point to the configuration file to use with the -c flag of
the s3cmd command, e.g.,
s3cmd -c ~/.s3cfg-lumi-46YXXXXXX ls
to list the buckets in project 46YXXXXXX.
Use lumio-conf -h to see how you can also create configuration files for aws and boto3.
It also has a bunch of other options.
Another way to configure tools for object storage access is simply via the code snippets
and configuration files snippets as has already been discussed before. The same snippets
should also work when you run the tools on a different computer.
E.g., for rclone you can add the code snippet to the configuration file
~/.config/rclone/rclone.conf (default name for Linux systems)
or replace an earlier code snippet for the same project in that file.
These code snippets can also be used to configure tools on
your own laptop or other systems that you have access to. As we have discussed already,
there is no difference in accessing LUMI-O from LUMI or from other systems if the same
tools are used.
Bucket and object names¶

We have already discussed that storage on LUMI-O is organised in three levels, each with a flat namespace:
- Projects,
- buckets and
- objects.
The project name is simply the 462 or 465 number of the LUMI project.
Bucket names have a lot of restrictions. The name should be unique within the project, but different projects can of course use the same bucket names. A bucket name should be between 3 and 63 characters long and can use only lowercase letters, numbers, hyphens and dots, but no uppercase letters or, e.g., underscores. It must also start with a lowercase letter or a number. Dots are considered as separators of labels, but the 63-character limit still applies to the name as a whole and not each individual label. The "label" term is a bit confusing as in the Ceph documentation it is also used in a totally different context.
Object names have fewer restrictions. They have to be unique within a bucket. From a technical point of view, an object name can be any UTF-8 encoded string between 1 and 1024 bytes. Note however that all but the standard ASCII characters use more than one byte in UTF-8 encoding, so this does not imply that any 1024-character string can be used. Also, client software may add more restrictions. It is a common practice to implement a folder-like structure using slashes in the name. Keep in mind though that creating that folder view (which we have seen in the Open OnDemand "Home Directory" app) is expensive as the client creating the folder view has to list all objects in a bucket and then sort and select the right entries to create the folder view.
Policies and ACLs¶

Access to buckets and objects is controlled through policies and access control lists (ACLs).
Policies are set at the bucket level only, but it is possible to build very complex policies that restrict access to some objects. It is a very powerful mechanism, but also one that is rather hard to use. In Ceph, the object storage system on LUMI, policies are a relatively new addition. Ceph policies are a subset of the policies on Amazon AWS S3 storage. There is some information on policies in the "Advanced usage of LUMI-O" section of the LUMI docs and the section on "Bucket Policies" in the Ceph Reef documentation is also relevant.
ACLs are a less sophisticated mechanism. They can be applied to both buckets and objects. However, they can only add rights and not take rights away. Moreover, they need to be applied to each object in a bucket separately (though commands will usually provide an option to apply them recursively to all objects in a bucket or maybe even pseudo-folder). They are an easy way though to make an bucket or an individual object public.
Note that a private bucket can contain public objects which you can then still see through, e.g., a web browser if you know the name of an object, or a bucket can be public but contain only private objects in which case you can only list the objects.
When using rclone on LUMI, specific access control lists will be attached to each object
depending on which end point name you have used.
Some examples¶

The s3cmd command is your friend if you want to inspect or change policies and
ACLs on LUMI. It is available via the lumio module.
-
You can make a bucket and all objects in it public with
s3cmd setacl --recursive --acl-public s3://bucket/(replace "bucket" with the name of the bucket) or private with
s3cmd setacl --recursive --acl-private s3://bucket/ -
You can grant or revoke read rights to a bucket with
s3cmd setacl --acl-grant=’read:465000000$465000000’ s3://bucket s3cmd setacl --acl-revoke=’read:465000000$465000000’ s3://bucketNote the use of single quotes as we want to avoid that the Linux shell interpretes
$465000000as a (non-existent) environment variable. And of course, replace "465000000" with your project number.One can also grant or revoke read rights to an object in a similar way.
-
Checking the current ACLs and more of an object, can also be done with the
s3cmdcommand.Some examples (but you cannot try them yourself as you'd need access credentials for the 462000265 project that contains those buckets and objects):
-
A bucket used to serve the images on this page:
s3cmd info s3://2day-20241210produces
s3://2day-20241210/ (bucket): Location: lumi-prod Payer: BucketOwner Ownership: none Versioning:none Expiration rule: none Block Public Access: none Policy: none CORS: none ACL: *anon*: READ ACL: LUMI training material: FULL_CONTROL URL: http://lumidata.eu/2day-20241210/Note the ACL "
*anon*: READ" in the output, showing that this is a public bucket. -
An example of an object in that bucket:
s3cmd info s3://2day-20241210/img/LUMI-2day-20241210-10-ObjectStorage/Title.pngwhere the output shows again that this is a public object:
s3://2day-20241210/img/LUMI-2day-20241210-10-ObjectStorage/Title.png (object): File size: 4384337 Last mod: Thu, 21 Nov 2024 14:55:47 GMT MIME type: image/png Storage: STANDARD MD5 sum: 69e1f1460cff3fca79730530e7fb28d7 SSE: none Policy: none CORS: none ACL: *anon*: READ ACL: LUMI training material: FULL_CONTROL URL: http://lumidata.eu/2day-20241210/img/LUMI-2day-20241210-10-ObjectStorage/Title.png x-amz-meta-mtime: 1732200870.757744714 -
However, if you try
s3cmd info s3://4day-20241028/files/LUMI-4day-20241028-1_01_HPE_Cray_EX_Architecture.pdfyou get
s3://4day-20241028/files/LUMI-4day-20241028-1_01_HPE_Cray_EX_Architecture.pdf (object): File size: 1299322 Last mod: Wed, 06 Nov 2024 09:28:35 GMT MIME type: application/pdf Storage: STANDARD MD5 sum: 9f2ec727731feba562c401fb0cb156c1 SSE: none Policy: none CORS: none ACL: LUMI training material: FULL_CONTROL x-amz-meta-mtime: 1730109719.352306659you see that there is no ACL "
*anon*: READ" as this is a private object, and even though the bucket it is in is public:s3cmd info s3://4day-20241028/shows
s3://4day-20241028/ (bucket): Location: lumi-prod Payer: BucketOwner Ownership: none Versioning:none Expiration rule: none Block Public Access: none Policy: none CORS: none ACL: *anon*: READ ACL: LUMI training material: FULL_CONTROL URL: http://lumidata.eu/4day-20241028/you'll see that, e.g., accessing https://462000265.lumidata.eu/4day-20241028/files/LUMI-4day-20241028-1_01_HPE_Cray_EX_Architecture.pdf or https://lumidata.eu/462000265:4day-20241028/files/LUMI-4day-20241028-1_01_HPE_Cray_EX_Architecture.pdf produces an "Access Denied" error message (in a strange format, but read the text), while https://462000265.lumidata.eu/2day-20241210/img/LUMI-2day-20241210-10-ObjectStorage/Title.png or https://lumidata.eu/462000265:2day-20241210/img/LUMI-2day-20241210-10-ObjectStorage/Title.png are links to the object used before in this example and work.
-
{kind=link}
{kind=link}
Sharing data¶


LUMI-O is also a nice solution to share data between projects and with the outside world. But note that this does not turn LUMI-O in a data publication and archiving service. There are specific services for that in Europe (e.g., EUDAT offerings). Each solution has its own limitations though:
-
Public buckets and objects can be read by anyone in the world, even with a simple web browser. Whether all objects can be listed or not, depends on the read rights of the bucket. But just as it is possible in Linux/UNIX to make a file readable in an otherwise unreadable directory (so an
lson the directory would not work), this is also possible on LUMI-O by using a private bucket with a public object.Using public objects is actually used to serve the slides and presentations in this course.
-
It is also possible to grant specific projects access to buckets and objects of another project. This is done via access control lists and has already been discussed in the previous examples.
The way to access those buckets and objects then differs between
s3cmdandrclone:-
As
s3cmdknows only one set of authentication tokens, it is not needed to indicate which credentials should be used if the~/.s3cfgfile is correct. E.g., listing all objects in the bucket "bucket" of project "46XXXXXXX" can be done with:s3cmd ls --recursive s3://46XXXXXXX:bucket/so you need to specify - as one could expect as the bucket namespace is per project - the bucket and the project that contains the bucket.
-
The
rcloneconfiguration file can contain multiple endpoints for multiple projects, so here we will also need to specify the endpoint from which the credentials should be used. Assume that a user in project 46BAAAAAA has been given read rights to the bucket "bucket" in project "46YXXXXXX" and has an endpointlumi-46BAAAAAA-privateconfigured, then that user can list the objects in that bucket with:rclone ls lumi-46BAAAAAA-private:"46YXXXXXX:bucket"
-
-
The third technique is using presigned URLs. These are URLs created specifically for access to a specific bucket or object. Everyone with the URL can access the bucket or object, without further authentication. It is possible to create a link with a limited validity period (and this is actually a good idea as URLs can fall in the wrong hands.)
Presigned URLs depend on the authentication key that was used to create them. If the authentication key expires or is revoked, the link will no longer be valid, even if this happens within the validity period of the link. It is not possible to create links with a validity period of more than 7 days on LUMI. Also, it is also possible to revoke the link.
Presigned URLs can be created and managed through the
rclone linkcommand. E.g.,rclone link --expire 2d lumi-46YXXXXXX-private:bucket/objectwill print a URL that can be used to access the object "object" in the bucket "bucket" of project 46YXXXXXX, and that link will expire automatically 48 hours after creation.
-
The most rudimentary method for data sharing with another user is of course to simply invite that user to the project. Then data can even be shared in the
/project,/scratchand/flashdirectory of the project and not only on LUMI-O.This is however not always possible.
-
Users that entered the system through Puhuri, i.e., a project with a project number starting with 465 cannot always be invited to a CSC project (projects starting with 462). They would first need to get a CSC userid to have access to myCSC and may end up with a second userID on LUMI.
-
Users who entered LUMI though myCSC, i.e., a 462 project, need to link their account first to MyAccessID or they would get a second userID on LUMI when invited by a Puhuri-managed project.
-
Tips & tricks¶

A description of the main rclone commands is outside the scope of this tutorial, but some options
are discussed in the LUMI documentation,
and the same page also contains some documentation for s3cmd and restic. See the links below
for even more documentation.
Note also that sharing data from project A with project B does not protect the data from being deleted when project A ends. If the data on LUMI-O is in the space of project A, then that data will be deleted after the 90-day grace period after the end of the project, even if project B is still a valid project. On LUMI-O, data is not deleted while a project is valid, is made read-only after the end of a project for a 90-day grace period, and is then queued for deletion, so just as for the Lustre filesystems, you need to move out the data in time.
Further LUMI-O documentation¶
- Documentation for the LUMI-O object storage service
-
Software for LUMI-O on LUMI is provided through the
lumiomodule which provides the configuration tool on top of the software and thelumio-ext-toolsmodule providing rclone, S3cmd and restic and links to the documentation of those tools.