Extreme-scale AI¶
Presenters: Paul Bauer (AMD)
Content:
- Model parallelism on LUMI via FSDP or DeepSpeed
- Scaling beyond a single node
Extra materials¶
Remark: Why is binding not easier in Slurm?¶
There are some reasons why the situation with the binding is not better:
-
Slurm GPU binding is broken and uses a technique that breaks communication with RCCL and GPU-aware MPI
-
One change that would offer some improvement is system-wide and would have a large impact on LUMI-C also, necessitating retraining all users and probably making some use scenarios on that partition difficult.
-
It is not easy either because you can only do something with few environment variables or a pre-made script if every user would nicely request 7 cores per GPU requested. On
small-gyou now basically have a lot of fragmentation. I'm not sure if "CPU" could be redefined in Slurm to mean "1 CCD" but that might very well be the change that sysadmins told me would also be in effect on LUMI-C where it would not be appreciated by users. -
And as we say in another course: "Slurm is not a good scheduler, but we don't have a better one yet". Current HPC schedulers were designed in the days that nodes had just one or 2 CPU cores and no accelerators and they don't sufficiently understand the hierarchy in resources and proximity between various components.
-
Preset are not easy. What may be ideal for some AI workflows may not work for others, or may not work for all the other users on LUMI that do simulation or other types of data processing and analysis.
Q&A¶
-
Is there a difference between
HIP_VISIBLE_DEVICESandROCR_VISIBLE_DEVICES? Are they aliases?ROCR_VISIBLE_DEVICESworks at a lower level in the software stack. It applies to all applications using the ROCm stack.HIP_VISIBLE_DEVICESonly works for applications using HIP under the hood. See also this page in the ROCm documentation
-
HIP is the CUDA-like abstraction layer? and ROCR to low-level GPU kernel layer? HIP is based on ROCR? ROCR is the related as ROCM?
- ROCR stands for ROCm Runtime. HIP is indeed AMD's alternative to CUDA, but ROCm is not only low-level. The runtime is, but ROCm also contains a lot of libraries with similar functionality as CUDA libraries, and then many of those libraries also have HIP alternatives, but that is then only a translation library that translate CUDA-like library calls to either the ROCm libraries when compiling on AMD or CUDA library calls when compiling on CUDA. For a more complete overview, see the "Introduction to the AMD ROCm Ecosystem" talk in the advanced training.
-
If building my own container, do I have to match the ROCm installation of LUMI (6.0.2) to a specific AWS-CXI plugin version?
- These are developed independently from one another with their own update schedules, so not that I know. AWS in the name actually stands for Amazon Web Services as it was developed to run on AWS's own ethernet implementation which also uses libfabric.
-
I tried adding aws-ofi-rccl to my own (sglang) container, but got out an error of "nid005018:47819:47913 [0] create_nccl_ofi_component:817 NCCL WARN NET/OFI Couldn't open a fabric access domain. RC: -38, ERROR: Function not implemented" for my troubles in the end. Any idea what caused this?
- You might need to bind some additional LUMI system libraries for this to work properly, i.e., the ones set in the
singularity-AI-bindingsmodel that was shown yesterday. As was mentioned yesterday, building the containers from scratch is not trivial since we cannot make all of the libraries needed available due to license restrictions. So it's usually best to start from the ROCm containers provided by AMD/LUST in/appl/local/containers/sif-images/and then use the additional binds to know that the basic setup is correct. - Lukas
I added libs from outside singularity until ldd was happy (except for warning ./librccl-net.so: /lib/x86_64-linux-gnu/libnl-3.so.200: no version information available (required by /lib/x86_64-linux-gnu/libcxi.so.1)).
As for basing on the LUMI images, I also have a workflow for that, but the problem is now that e.g. vLLM and sglang both do so many tweaks and things in their own Docker builds that matching them on top of a LUMI image starts to be insanely complex. Would be reaaaaaally much nicer if it could be made easier to inject the required additional LUMI stuff on top of these images
- For vLLM in particular there are pre-built containers for LUMI.
Yes, but they have too old vLLM versions ;). I did get a new vLLM built on top of the LUMI container but it was a pain. And for sglang, there's even more complexity.
- At least with the CSC PyTorch you should be able to add newer vLLM like this (e.g. with venv) singularity recipe, line 144
CSC PyTorch on LUMI BTW doesn't seem to have aws-ofi-rccl?
- Yes it does have aws-ofi-rccl, but if you don't use the module load it might not set the right bind paths to get libcxi etc from the host.
Oh. Where is it in the container? Couldn't find it when I was trying. Ah, okay, found it in
/usr/local/lib/librccl-net.so.- The CSC PyTorch is built with the definition file linked to above, so you can check from there.
Anyway, the core point is that a) stuff like vLLM and sglang move forward now so fast that using versions from even a month ago is both limiting and inefficient, and b) trying to reproduce their builds on top of a custom container is hard, particularly because the Dockerfile.rocms for both are starting to include all kinds of important tweaks in themselves in complex hierarchies, e.g. https://github.com/vllm-project/vllm/blob/main/Dockerfile.rocm -> https://github.com/sgl-project/sglang/blob/main/docker/Dockerfile.rocm . So, an option to flip the tables and a workflow/instructions for instead injecting the LUMI special requirements on top of the base ROCM images would be extremely welcome.
- I would assume you can also add aws-ofi-rccl on top of one of those containers (+ plus bind libcxi), although I haven't tried that myself.
Yeah, well I tried that on top of the sglang image and got the error in the initial question :D. So, someone from LUST/CSC trying this on various images and writing instructions + observations on what needs to be taken into account for this to work would be awesome.
-
What you ask with "flip the tables", is simply not possible. Containers are not portable enough. If the developers of the container don't take LUMI requirements also into account when building their containers, there is no way to inject them afterwards.
Contrary to popular belief, containers are not a miracle solution for portability. They rely on hardware properties, OS kernel, driver versions, etc., and if those are different, you may not be able to run the container on your system.
There is even no universal way to inject other libraries in the container, as what you need to inject, depends on what is already in the container, and the library versions needed by stuff you inject in a container, may conflict with the versions that are already in a container.
If you want that ease-of-use, your only solution is to request compute time on a system that is as similar as possible to the one that the developers of those containers use.
-
Partially yes, but what I envision is some kind of an accounting of precisely the boundaries here. Not looking for being able to run ready container off the bat on LUMI, but on more rounded info on what exactly needs to be tuned for LUMI, so that I could better know how I need to modifty them. For example, the CSC container seems to build off of rocm/dev-ubuntu-22.04:6.2.4-complete, which is very alike the sglang ROCM container I was trying to get working (and unlike the LUMI host system). And okay, the aws-ofi-rccl seems to be working on the CSC version and not on my current sglang attempt, so clearly there are intricacies here that can't be fully explored, but I'd basically be happy with even just some "implementation notes" on issues the CSC and/or LUST people encountered when building your containers, from which starting point triaging the issues would be easier. Like, there are recipes now for mounting some required libs into singularity from outside, but I haven't seen a clear explanation anywhere on why exactly this is necessary. I assume libcxi is the key piece of proprietary code that can't be packaged/built in the container? But then, next step, what are e.g. its boundaries in terms of the versions of libraries it requires to work, and could they be mapped somehow? Could libcxi be linked statically so that it would not depend on further sos? Is also libfabric something that strictly needs to be mounted from the outside/version matched? etc...
-
Nobody knows all those boundaries, not even the developers of those libraries as they have only been tested on those OS versions that are relevant to them. You have to understand that Linux is not compatible with Linux due to too many different distributions. So the approach within LUST is to stick to a build as close as possible to the system, which is why we tend to start from a SUSE distribution equivalent to the one on LUMI. So at the moment, we'd use, e.g., OpenSUSE 15 SP5. Testing the things that you would like to be tested, is really a combinatorial problem as there are so many libraries involved...
Completely understand. Would still appreciate even more "notes-style" writings attached to the EasyBuild scripts etc outlining the reasons for everything. Much of this is already there, but not the "non-end-user"-facing parts, which are interesting for people who'd like to not only use what is there, but to build off it.
- You might need to bind some additional LUMI system libraries for this to work properly, i.e., the ones set in the
-
Is
export NCCL_SOCKET_IFNAME=hsn0, hsn1, hsn2, hsn3equivalent toexport NCCL_SOCKET_IFNAME=hsn?- Yes, I believe so. If it works according to NVIDIA docs: https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/env.html#nccl-socket-ifname .
- Unfortunately, I cannot find a proper explanation in the ROCm documentation which only suggests the first form.
- The CSC PyTorch module on LUMI uses the latter form and it appears to work correctly :-)
-
If I make my own container, is there some documentation how to setup RCCL correctly? In my context, I will not PyTorch (using julia...) but I plan to use the generic rocm containers from LUMI (e.g.
/appl/local/containers/sif-images/lumi-rocm-rocm-6.2.2.sif).-
If you have ROCm installed in your container, RCCL will be installed with it. These days, the latest pytorch wheel files also comes with RCCL. So typically, you don't need to do anything to setup RCCL as the right defaults are already used. If you install pytorhc yourself from their official drops in https://download.pytorch.org/whl/torch/, make sure you use a version that matches the ROCm version in the container. If you use other frameworks you can leverage RCCL that comes with ROCm.
-
For performance you have then to have the CXI plugin. This is a runtime dependency, so it only needs to be in your LD_LIBRARY_PATH or installed in a folder your container loader will look for dynamic libraries.
-
If you use the LUMI provided container, the plugin is already installed for you. No special setup that needs doing.
-
export NCCL_DEBUG=INFOis your friend to understand the plugin is being picked up.
-
-
I would like to understand better what is the difference between RCCL (or NCCL) and the slingshot network. The first is related to communication between the GPUs on a node and the other between the nodes?
-
Slingshot is the name for a piece of hardware. As every piece of hardware, it comes with a driver and some user level software components, e.g., the CXI provider which connects the driver to the standard libfabric library. RCCL/NCCL is a communication library that works at a slightly higher level in the communication stack. As RCCL by default cannot talk to libfabric but only to UCX which is yet another library not supported on the Slingshot hardware and driver, or fall back to regular TCP/IP sockets, it needs a plug-in to let it talk to libfabric and that is where the AWS plugin comes in the story.
RCCL is part of the ROCm software stack and mimics NCCL which is a library in the NVIDIA CUDA stack. We need RCCL to connect to libfabric.
libfabric is an open-source network library used by a lot of network vendors.
libfabric then uses the CXI provider to talk to the Slingshot driver and hardware. CXI is proprietary but being open sourced currently by HPE, but there are still problems with the open source build (and it also seems to be for a newer version of the network driver than we have).
The C in CXI actually stands for Cassini which was the code name for the network interface card during the development.
-
-
For large/extreme scaling of models which require model/tensor/pipeline parallelism, what is the best way to check scaling efficiency (weak vs strong?)
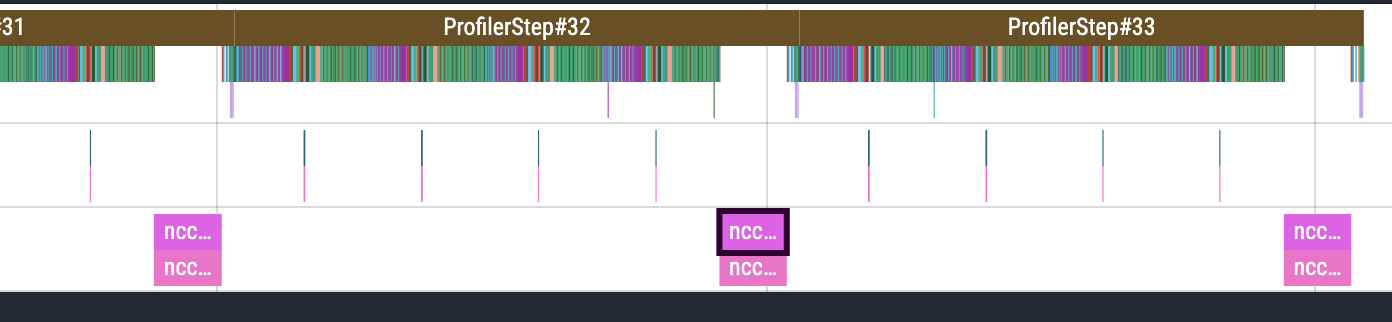
- Strong usually means your local batches to decrease proportionally with the GPUs whereas weak will keep the local batches and have more data processed in a given time window. So the Weak vs strong setup has to be defined by the user according to the needs of their model. Then, to check the behaviour I recommend using the pytorch profiler infrastructure that leverages rocprof libraries under the hood - check the monitoring slides of lesson 4. With the resulting file, you can then load in https://ui.perfetto.dev. You can see things like the image below. The purple pieces with nccl in the name are communication. I can see exactly the proportion of the time spent in communication. You can also do other things like zooming in and see if there are gaps, with no activity, meaning that you might be bound by CPU or even I/O. There are also ways to show summarise of the information.
-
I did not quite understand the
-cpu-bind=mask_cpu:0xfe000000000000,.... How does the option change when we change the number for CPUs/GPUs?- The idea behind the setup of a mask is to guide SLURM to use a given set of CPUs for increasing ranks.
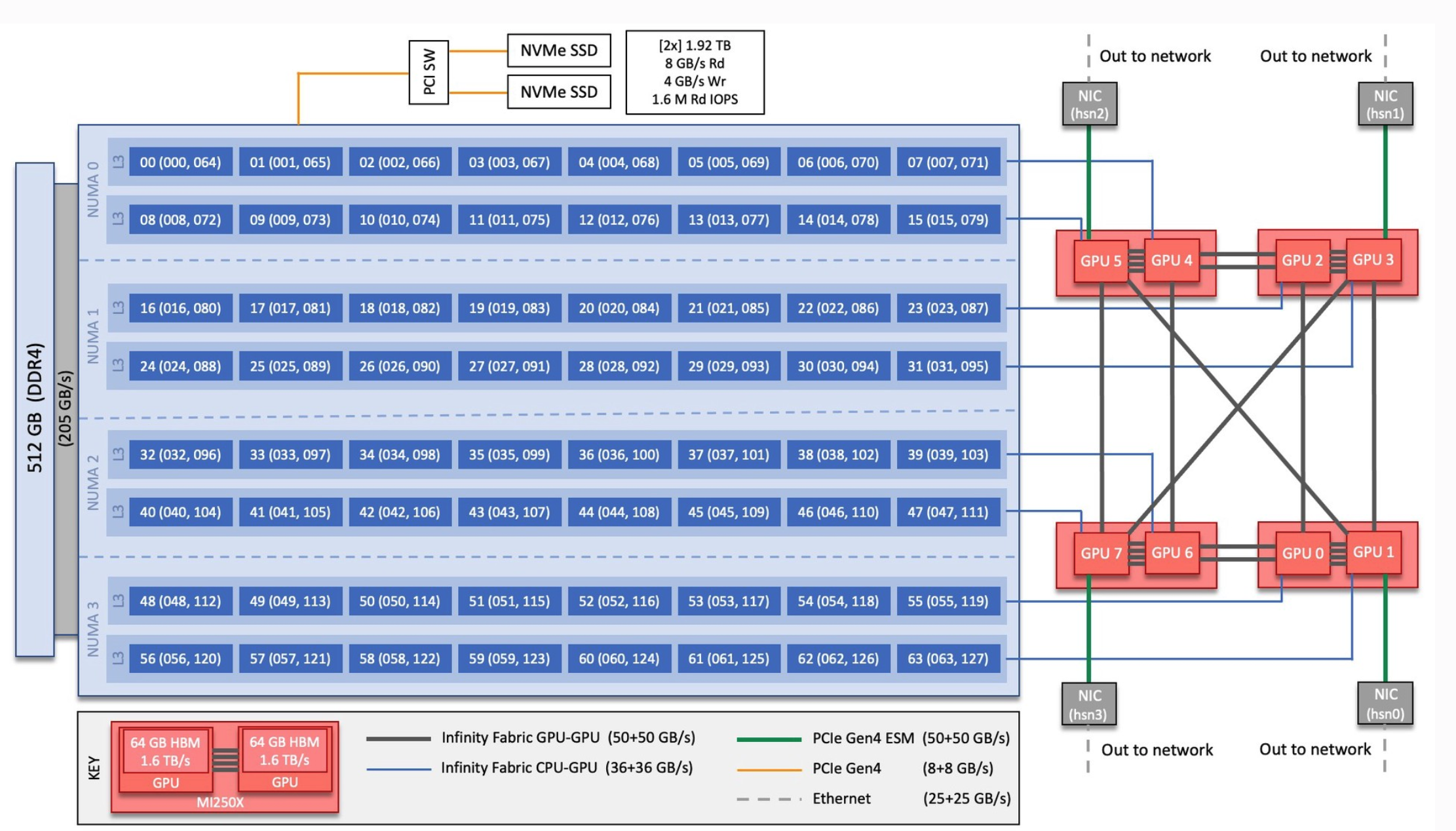
As stated in the talk, frameworks make assumptions on which GPU to use for a local rank, so typically rank 0 uses GPU 0, rank 1 uses GPU 1, etc. Extrapolating beyond the node you will get rank N using the GPU N%Number_Of_GPUs_Per_Node. So, this is the assumption we start from. Now, we need to assign CPUs properly to this assumption. For this we can use the reference image below. There we see that GPU 0 is connected to CPUs 48 to 55. We also know that LUMI reserves the first CPU of each L3 domain, so we will have 49 to 55. SLURM can take this information as a bit mask and that is what goes in the
-cpu-bind=mask_cpu:option. In binary the mask for our 49-55 CPus would be:11111110000...0000(with 49 zeros). We then use the hexadecimal representation of this bit mask in the option. We repeat this for every GPU, hence we will have 8 masks. SLURM uses this mask in a round-robin fashion, so when you get to the second node (rank 8 onwards) it applies the mask list from the start.
- The idea behind the setup of a mask is to guide SLURM to use a given set of CPUs for increasing ranks.
As stated in the talk, frameworks make assumptions on which GPU to use for a local rank, so typically rank 0 uses GPU 0, rank 1 uses GPU 1, etc. Extrapolating beyond the node you will get rank N using the GPU N%Number_Of_GPUs_Per_Node. So, this is the assumption we start from. Now, we need to assign CPUs properly to this assumption. For this we can use the reference image below. There we see that GPU 0 is connected to CPUs 48 to 55. We also know that LUMI reserves the first CPU of each L3 domain, so we will have 49 to 55. SLURM can take this information as a bit mask and that is what goes in the
-
Should we set up cpu-bind-mask if we are using less than 8 GPUs?
-
You cannot do proper binding if you are not on an exclusive node as you don't know which cores and which GPUs you will get. Unfortunately, not doing proper binding also comes with a performance penalty. Ideally you would "right-size" the computer you use with the problem you're trying to solve, and LUMI nodes are just too big for users with smaller problems to be fully efficient.
This talk tries to compress materials that take a lot more time in our introductory course to explain all details... E.g., it is an important part of the "Process and Thread Binding" talk in the introductory course.
-